Tutorial
In this part of the documentation we try to dive in the functions of itertree in a clear structured way. The user might look in the class description of the modules too. But the huge number of methods in the iTree class might be very confusing. We hope these chapters orders the things in a much better way so that the user get’s used to the class as quick as possible.
It’s recommended to have a look on the related examples too (stored in the example folder of itertree).
Status and compatibility information:
The original implementation is done in Python 3.9.
This release is tested in different OS for the Python versions:
3.6, 3.7, 3.8, 3.9, 3.11, 3.12, 3.13
It should work for all Python versions >= 3.4.
From version 1.0.0 on we see the package as released and stable. The unit and integration test suite should target a huge amount of functionalities and use cases. We will try to keep the interface stable too.
Quick start - the basics
We really hope that the usage of the itertree package is intuitive. If the user is familiar with list and dict objects the basic functionality should be easy to understand. If you extend the functions to nested lists or dicts you already get a tree like structure. What is really a bit complex are the functions related to tree iterations and filtering but of course the “simple” iteration like in the other objects are available too.
Build the object
Each tree item contains two sub-elements the value (data-object) that can be stored in the item and the subtree of children. The base class that must be instanced to build the trees is iTree and you can simply append sub-items.
>>> # Instance an iTree object by giving a tag, value and two subtree items (children):
>>> root = iTree('root', value=0, subtree=[iTree('item0', value=0), iTree('item1', value=1)])
>>> # append additional child with same tag!
>>> root.append(iTree('item1', value={'value1':2,'value2':3})) # any object can be used as values
iTree('item1', value={'value1': 2, 'value2': 3})
>>> # list like operations are supported; e.g. insert():
>>> root.insert(2,iTree((1,2), value=3)) # any hashable object can be used as tag
iTree((1, 2), value=3)
>>> # extend the tree by one more level
>>> root[1].append(iTree('sub_item0',0.1))
iTree('sub_item0', value=0.1)
>>> root[-1].append(iTree('sub_item0',4.1))
iTree('sub_item0', value=4.1)
>>> root.render()
iTree('root', value=0)
> iTree('item0', value=0)
> iTree('item1', value=1)
. > iTree('sub_item0', value=0.1)
> iTree((1, 2), value=3)
> iTree('item1', value={'value1': 2, 'value2': 3})
. > iTree('sub_item0', value=4.1)
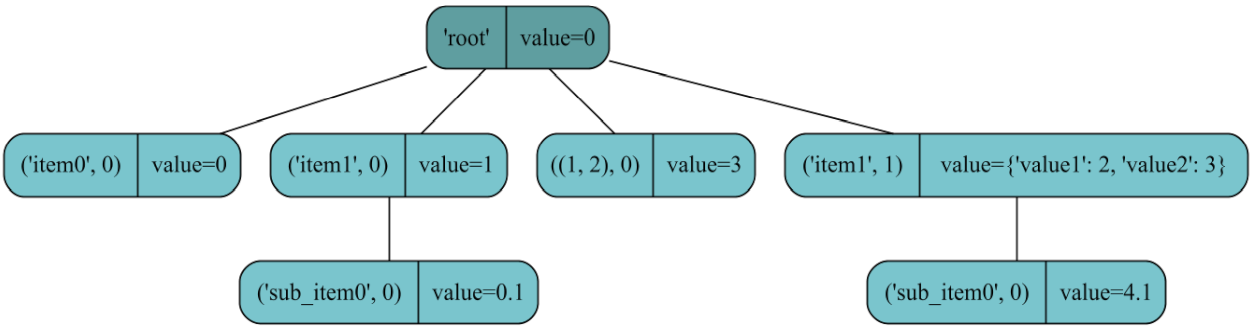
Figure representing the resulting iTree-object each item represented by a rounded box (left-side: tag-idx; right-side: value object)
Note
IMPORTANT: In itertree you can append items with the same tag multiple times. Those items are collected in a “tag-family”. As tag you can use any hashable object.
Access the items
Item access is possible via __getitem__(target) ( usage via: my_tree[target] ). The method supports different types of targets and delivers returns related to those.
You can target a single item via absolute index or you can target it via tag-idx-key (this key is unique).
Note
The tag-idx-key is a tuple: (tag, family-index) . The family-index is the relative index of the item inside the tag-family. Inside the iTree-object the children are ordered and they keep the same order inside their tag-family.
In case the target is only the tag (without the tag-family-index) the method will deliver the whole tag-family as a list (multi-items-target).
>>> # Target a child in the tree via absolute index:
>>> root[1]
iTree('item1', value=1, subtree=[iTree('sub_item0', value=0.1)])
>>> # Target a child in the tree via tag-idx-key:
>>> root[('item1',0)]
iTree('item1', value=1, subtree=[iTree('sub_item0', value=0.1)])
>>> item=root[('item1',1)] # given index is the tag-family index in this case
>>> item.idx # delivers absolute index of the item
3
>>> item.tag_idx # delivers tag-index-key of the item
('item1', 1)
>>> item.parent # delivers the parent object of the item
iTree('root', value=0, subtree=[iTree('item0', value=0),...,iTree('item1', value={'value1': 2, 'value2': 3}, subtree=[iTree('sub_item0', value=4.1)])])
>>> # if you give just the family tag without index the whole tag-family is given as a list
>>> root['item1']
[iTree('item1', value=1, subtree=[iTree('sub_item0', value=0.1)]), iTree('item1', value={'value1': 2, 'value2': 3}, subtree=[iTree('sub_item0', value=4.1)])]
Iterate over the items
As the name of the package implies we have multiple iterators available.
>>> # Standard iterator over the children:
>>> [i.value for i in root]
[0, 1, 3, {'value1': 2, 'value2': 3}]
>>> # iteration over items (like in dicts):
>>> [i for i in root.items()]
[(('item0', 0), iTree('item0', value=0)), (('item1', 0), iTree('item1', value=1, subtree=[iTree('sub_item0', value=0.1)])), (((1, 2), 0), iTree((1, 2), value=3)), (('item1', 1), iTree('item1', value={'value1': 2, 'value2': 3}, subtree=[iTree('sub_item0', value=4.1)]))]
Copy and Compare
A copy of an iTree-objects implies a copy of all children. The compare operation == is an in-depth operation too (compare all children and sub-children inside (same tags, values and order?)). But a match means “just” that we have an equal object and not the same object-instance as we see:
>>> # Copy the iTree:
>>> new_tree=root.copy()
>>> # compare:
>>> new_tree==root
True
>>> # and see we have different objects:
>>> new_tree is root
False
>>> # and all sub-items are copied too:
>>> new_tree[0] is root[0]
False
>>> new_tree[1][0] is root[1][0]
False
In-depth operations
The itertree is a nested tree-structure and it supports in-depth operations out of the box. As we have already seen some functions in the base-class contains direct in-depth support (we saw already copy(), == and now follows the important function get()).
Additional in-depth functionalities (especially deep-iterators) can be found in the sub-class iTree.deep.
>>> # To access items in-depth target_paths can be given as parameters to get()
>>> target_item=root.get(('item1',1),0) # target types can be mixed (e.g. tag-idx and absolute index)
>>> # Get method delivers flatten lists in case multiple items are targeted (even in higher levels)
>>> root.get('item1',0) # delivers all matches in deepest level!
[iTree('sub_item0', value=0.1), iTree('sub_item0', value=4.1)]
>>> # other in-depth operation are found via .deep:# contains (target-item of first get operation):
>>> target_item in root # item is not a level 1 child!
False
>>> target_item in root.deep # but item is part of the tree (in-depth)
True
>>> # size:
>>> len(root)
4
>>> len(root.deep)
6
>>> # flatten iterators over all in-depth items:
>>> [i for i in root.deep] # up-down order
[iTree('item0', value=0), iTree('item1', value=1, subtree=[iTree('sub_item0', value=0.1)]), iTree('sub_item0', value=0.1), iTree((1, 2), value=3), iTree('item1', value={'value1': 2, 'value2': 3}, subtree=[iTree('sub_item0', value=4.1)]), iTree('sub_item0', value=4.1)]
>>> [i for i in root.deep.tag_idx_paths(options=ITER.UP)] # tag_idx related iterator; down-up order
[((('item0', 0),), iTree('item0', value=0)), ((('item1', 0), ('sub_item0', 0)), iTree('sub_item0', value=0.1)), ((('item1', 0),), iTree('item1', value=1, subtree=[iTree('sub_item0', value=0.1)])), ((((1, 2), 0),), iTree((1, 2), value=3)), ((('item1', 1), ('sub_item0', 0)), iTree('sub_item0', value=4.1)), ((('item1', 1),), iTree('item1', value={'value1': 2, 'value2': 3}, subtree=[iTree('sub_item0', value=4.1)]))]
Save and load
The itertree package delivers a standard serializer which stores the iTree-object in a JSON formatted file. It supports the serialization of more complex value-objects (e.g. numpy-arrays).
>>> # save tree to file
>>> root.dump('dt.itz',overwrite=True) # returns the sha1 hash of the tree stored in the file
fb2a60c29acc2119363831ad1039c00836e55d15eb36955617d1c913f86dc8eb
>>> # load tree from file
>>> loaded_tree=iTree().load('dt.itz')
>>> loaded_tree==root
True
Note
The iTree-class uses iterative and no recursive algorithms. The advantage is that the object will not raise RecursionErrors even if user defines very deep trees (e.g. see the performance-analysis with a tree depth of 1000 levels). To keep the functionality for the stored data the serializer creates a flat list of entries (which avoids RecursionErrors related to the JSON parser).
Use iTree as super class
If the user wants to extend the functionalities or to make the class compatible with an already existing implementation the iTree class might be used as a super class (possible since new release 1.1.0).
Warning
Overloading the orignal methods is very risky because they might be used internally. Changes must consider this and other methods might be overloaded to to ensure that super functions are used.
Serializing the new class should be possible in general (e.g. the class is just extended with additional methods. If the stored data content is changed (not only .value is used) the serializer must be rewritten too to ensure that the new data is reconstructed during load.
In the examples we have added a module itree_like_anytree.py which overloads the iTree() class so that it behaves partly like anytree (we did not check all details it’s just an example). The module might be a good starting point for the use case.
Next steps
After those basic functions are learned you may be motivated to dive deeper. E.g. learn more about possible targets related to item access, linking trees and branches, search/filter in the trees and store more advanced datatypes in the tree.
Introduction to the iTree class
As a starting point the iTree-class should be seen as a list (the object inherits his functions from a list or blist). All typical list like methods are available. But iTree-objects supports also in-depth access and iterations over different levels of the nested tree structure. In a second abstraction level iTree-class supports the more dict-like access functions related to keys too.
For a functional comparison in between ìTree, list and dict the table in the chapter Comparison of the iTree object with lists and dicts might be interesting for the reader.
Unique parent principle
We have one important limitation related to iTree objects, each one can only be the child of ONE PARENT ONLY!
If the users tries to append an iTree-object that is already a child of an iTree to another iTree a RecursionError will be raised.
Only if the iTree referencing feature iLink() is utilized the share of same objects in different tree-sections is possible.
To avoid issues in some multi-item-functions implicit copies are created automatically (e.g.: my_tree.extend(itree) or rearrangements via itree[1],itree[2]==itree[2],itree[1] or multiplications like my_tree= itree * 10).
Note
The terms itree and my_tree are used as examples of instanced objects in this tutorial.
In case of implicit copies the objects copy()-method will be used. The method is an in-depth copy of all sub-items (required because of one parent only principle) and the method creates also a copy of the stored value object (top-level-only). It is an iterative equivalent to the operation:
new_itree=iTree(itree.tag,copy.copy(itree.value), subtree=[i.copy() for i in itree])
Warning
If it is required to keep the original objects the operations:
multiplication of iTree-objects
build iTree-object based of children of another iTree (e.g. new_tree=iTree(subtree=old_tree))
rearrangements like itree[1],itree[2]==itree[2],itree[1]
must be avoided!
Naming conventions
In the itertree package and this tutorial the following naming convention is used:
- item
An item is an iTree object that is a child (sub-element) of an iTree parent object somewhere inside the nested tree structure.
- parent
The current object can be the child of a specific parent or it has no parent. A child can have only one parent. All parent related properties will deliver None in case no parent is coupled to the object (e.g. itree.idx, itree.key,`itree.parent`, …).
- child
An iTree object that has a parent. This object is part of the parents children and it is related to the absolute order of them and to its family siblings.
- root
For nested children in sub-sub-trees the root is the top level parent. Any iTree object that has no parent is a root object itself.
- family
The group (list) of children in an iTree that have the same tag (The children have same order in the family as in iTree-object (absolute order)).
- tag
The tag is a object that defines that the item is part of a specific family. If no tag is given automatically the NoTag object will be used as tag. The user can use any hashable object as a tag for an iTree-object.
- idx
Specific (unique) index of a children related to the absolute order of the iTree’s children (list like access)
- tag-idx
Specific (unique) tuple of family-tag and family-index of an ´iTree´ child (sometimes named tag-idx-key).
- idx_path
Specific (unique) tuple of indexes (index per level) describe the path from the root parent object to the specific nested child somewhere deep in the iTree object. E.g (0,1,0) targets:
element (level 0) ->
element (level 1) ->
element (level 2)
In access function the relative idx_path from the current object to the sub-item must be given. The absolute path to the root makes only sense if it used related to the root object: itree.root.get(*absolute_idx_path).
- tag_idx_path
List of tag-idx-keys (unique tuples of family-tag,family-index) describe the path from the root object to the specific nested child somewhere deep in the iTree object. E.g ((‘tag1’,0),(NoTag,1),(1.6,0)) targets:
element in tag-family ‘tag1’ (level 0) ->
element in tag-family NoTag (level 1) ->
element in tag-family 1.6 (level 2)
In access function the relative tag_idx_path from the current object to the sub-item must be given. As for idx_paths the absolute path can be utilized related to thr root object: itree.root.get(*absolute_tag_idx_path))).
- target
Is an object that targets one or multiple items in an iTree the target is used related to one level only. But to reach deeper levels the user can create based on targets target_paths (list of targets).
The common access methods __getitem__() , get() are sensitive related to the given target and a related object will be returned:
Single target definitions deliver a single item.
Multi target definitions deliver a list (or blist ) of items.
Possible target definitions are:
index - absolute target index integer (fastest operation) -> unique/single result
tag_idx - key tuple (family_tag, family_index) -> unique/single result
tag-set - {family_tag} object targeting a whole family -> list result
tag-sets - {family_tag,family-tag2,…} object targeting multiple families -> list result
target-list - indexes or keys or other targets (mixed lists support). Selects items in same level based given target-list -> list result
index slice - slice of absolute indexes -> list result
tag_idx_slice - tuple of of (family_tag, family_index_slice) -> list result
filter_method - a filtering method that delivers True/False related to an analysis of item properties -> list result
iter_method - if build-in iter is given a list of all children will be delivered (same like list(itree.__iter__())
Ellipsis - if Ellipsis … is given a list of all children will be delivered (same like itree[:])
- target-path
The target-path is a list of targets and it is used for in-depth operations over the different nested levels of the tree. Most often (e.g. get(*target_path)) the target-path is given as a pointer argument to the method.
Note
Please understand the difference in between a target-list and a target_path.
target-list -> targets items in the same level (siblings)
target-paths -> targets items in different nested levels, this is an in-depth access
In the related methods (e.g. get()) target-list are given as one parameter but target_paths are given as multiple parameters.
itree.get([1,2,3])~[itree[1],itree[2],itree[3]] -> targets the children [1][2][3] in level 1
itree.get(*[1,2,3])~itree[1][2][3] -> targets the item [1] in level 1, [2] in level 2 and [3] in level 3
If the user defines a target-path like my_path=[[1,2],[0,1]] the object will be seen as a target_path of target_list-targets. E.g. such a list can be used in my_tree.get(*my_path)) (give pointer). The input is the same like get([1,2,3,4],[9,10]). The result of the request is a flatten iterator over all matches in the deepest requested level but it will considering all multi-matches in the levels inbetween too.
>>> root = iTree('root') >>> root.append(iTree('a', value={'mykey': 1}, subtree=[iTree('a1'), iTree('a2')])) iTree('a', value={'mykey': 1}, subtree=[iTree('a1'),iTree('a2')]) >>> root.append(iTree('a', value={'mykey': 1}, subtree=[iTree('a1'), iTree('a2')])) iTree('a', value={'mykey': 1}, subtree=[iTree('a1'),iTree('a2')]) >>> root.get([0, 1], [0, 1]) [iTree('a1'), iTree('a2'), iTree('a1'), iTree('a2')]
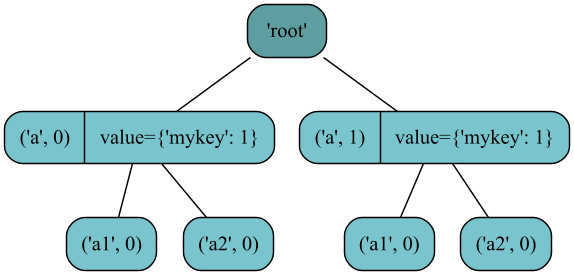
Figure showing the resulting iTree
- value
The value is the a data-object that can be stored in a iTree-object
Name extensions:
- s
If plural is used in method names this is a hint that the method return will be an iterator: e.g.: itree.keys(); itree.values(); itree.items(); itree.deep.tag_idx_paths(); itree.deep.idx_paths()
- _path
The extension is used for parameters and properties. This means that the parameter is an iterable that targets the different levels of the nested structure (in-depth access). e.g. get(*target_path)
- filter_method
A method that check the match of a iTree-item related to a property and the method delivers True/False if an iTree-item is given as parameter. Therefore the method can be used for the filtering of items.
Internal helper classes:
- .deep
Helper class contains the in-depth functions that targets all elements inside the iTree-object. E.g. the class contains different flatten iterators that iterates over all nested items of the iTree-object. The class contains no __getitem__() method for in-depth item access because the function is already covered by the standard get() and get_single() methods. The available get()-method is the same as the get()-method in the base class. (in detail: iTree full overview over the in-depth functionalities)
- .getitem
Helper class that contains a lot of specific getitem methods f<or the different possible targets. (in detail: Item Access)
Construction of an itertree
The first step in the construction of a itertree is to instance the main itertree class: iTree.
- class itertree.iTree(tag=<class 'itertree.itree_helpers.NoTag'>, value=<class 'itertree.itree_helpers.NoValue'>, subtree=None, link=None, flags=0)[source]
Instance the iTree object:
>>> item1 = iTree('item1') # itertree item with the tag 'item1'
>>> item2 = iTree('item2', 2) # instance a iTree-object with value content integer 2
>>> item2b = iTree('item2', {'mykey': 2}) # instance a iTree-object with a dict as value content
>>> item3 = iTree() # instance an iTree-object with the default tag (==NoTag) and no data content (==NoValue)
>>> root = iTree('root', subtree=[item1, item2, item2b, item3])
>>> root.render()
iTree('root')
> iTree('item1')
> iTree('item2', value=2)
> iTree('item2', value={'mykey': 2})
> iTree()
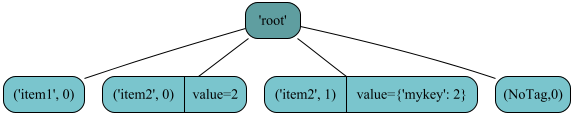
Figure showing the resulting iTree
To include iTree-objects as a children in a parent object we have several possibilities, those functionalities are comparable to the same methods you find in list-objects.
>>> root = iTree('root')
>>> root.append(iTree('child')) # append a child
iTree('child')
>>> # The append operation delivers the appended object back
>>> root += iTree('child') # alternative way to append a child
>>> root.append('value_content') # append a child with implicit iTree(tag=NoTag,value='value_content')
iTree(value='value_content')
>>> root.insert(1, iTree('child','inserted')) # insert the item in the given target position (the insert is done in this target (index)
iTree('child', value='inserted')
>>> # the old item with given target (index) will be moved in next position
>>> root.render()
iTree('root')
> iTree('child')
> iTree('child', value='inserted')
> iTree('child')
> iTree(value='value_content')
>>> root[0] = iTree('newchild') # replace the child with index 0
>>> root.render()
iTree('root')
> iTree('newchild')
> iTree('child', value='inserted')
> iTree('child')
> iTree(value='value_content')
>>> del root[('newchild', 0)] # deletes the child with key=('newchild',0) family-tag='newchild' and family-index=0
>>> root.render()
iTree('root')
> iTree('child', value='inserted')
> iTree('child')
> iTree(value='value_content')
>>> del root[1] # deletes the child with absolute index 1
>>> root.render()
iTree('root')
> iTree('child', value='inserted')
> iTree(value='value_content')
>>> # The tag can be any hashable type!
>>> root.append(iTree(1)) # append a child with tag 1
iTree(1)
>>> root.append(iTree((1, 2, 3))) # append a child with tag (1,2,3)
iTree((1, 2, 3))
>>> root.append(iTree((1, 2, 3), 1)) # append a child with tag (1,2,3) and data content 1
iTree((1, 2, 3), value=1)
>>> root.render()
iTree('root')
> iTree('child', value='inserted')
> iTree(value='value_content')
> iTree(1)
> iTree((1, 2, 3))
> iTree((1, 2, 3), value=1)
>>> new_itree = iTree()
>>> root.append(new_itree)
iTree()
>>> root.append(new_itree) # appending same object again will not work because parent is already set
Traceback (most recent call last):
...
RecursionError: Given item has already a parent iTree!
Remember if a tag is appended in an object where already exists a child with same tag this/those child/children will not be overwritten! Furthermore all items with same tags are collected in the same tag-family:
>>> family=root[{(1,2,3)}] # target the family with a set(): {(1,2,3)}
>>> family # is represented as a list of the related items (with same tag)
[iTree((1, 2, 3)), iTree((1, 2, 3), value=1)]
>>> family=root.get.by_tag((1,2,3)) # target via the s�ecial tag access function
>>> family # is represented as a list of the related items (with same tag)
[iTree((1, 2, 3)), iTree((1, 2, 3), value=1)]
Additionally a huge set of methods is available for structural manipulations related to the children of a item.
- itertree.iTree.append()
Append the given iTree-object to the iTree (new last child) The append() method is the fastest way to add a single item to the end of the tree.
- Except:
In case iTree-object has already a parent a RecursionError will be raised Other exceptions might come up in case the iTree is protected (tree read-only mode).
- Parameters:
item (Union[iTree,object]) –
iTree-object to be appended
Warning
In case the given item-object is not a iTree-object the item is interpreted as a value and the iTree will be created implicit (with tag-family NoTag) in the way:
iTree(tag=NoTag, value=item) ~ ìTree(value=item) If no item is given an empty iTree is created tag=`NoTag`; value=`NoValue`.
>>> root=iTree('root') >>> root.append('myvalue') iTree(value='myvalue') >>> root.append() # append an empty iTree-object iTree()
- Return type:
- Returns:
Delivers the appended item itself (it might be useful for the user to get the updated information of the object).
- itertree.iTree.__iadd__()
append the given item to the iTree (short form of append())
- Except:
In case iTree-object has already a parent a RecursionError will be raised Other exceptions might come up in case the iTree is protected (tree read-only mode).
- Parameters:
other (Union[iTree,object]) –
iTree-object to be appended.
Warning
As in append() in case the given item-object is not a iTree-object the item is interpreted as a value and the iTree will be created implicit (with NoTag tag).
- Return type:
ìTree
- Returns:
self
- itertree.iTree.appendleft()
Append the given iTree-object to the left of the parent-tree (new first child) The appendleft() method is the recommended method to add a new first item to iTree (quicker than insert(0,item) ). Compared to append() the method is slower and the cache index information gets invalid after the operation (will be automatically updated later on if required).
- Except:
In case iTree-object has already a parent a RecursionError will be raised. Other exceptions might come up in case the iTree is protected (tree read-only mode).
- Parameters:
item (Union[iTree,object]) –
iTree-object to be appended as first item.
Warning
As in append() in case the given item-object is not a iTree-object the item is interpreted as a value and the iTree will be created implicit.
- Return type:
- Returns:
Delivers the appended item itself (it might be useful for the user to get the updated information of the object).
- itertree.iTree.extend()
We extend the iTree with given items (multi append). The function is high performant and if you have to append a large number of items it is recommended to create an iterator of the items and feed them into this method. This is quicker compared to a loop doing multiple normal append() operations.
Note
In case the to be extended items have already a parent an implicit copy will be made. We do this because the internal copy can be created more effective. We accept also iTree-objects as extend_items parameter and the children which have a parent will be automatically copied to be integrated in this second tree. We have the same situation with a filtered iterator which might be used to extend this iTree too.
- Parameters:
items (Iterable) –
iterable-object that contains iTree-objects as items it can be:
iterator or generator of iTree-objects (using next)
iTree-object (children will be copied and extended in this tree)
iterable of iTree-objects (list, tuple, …)
argument list for iTree-instance ( ´__init__()´ ) (created by ´get_init_args()´ or ´get_init_args_deep()´ ) -> this is most often an internal functionality.
iterator or generator of value-objects (using next) - implicit iTree-objects created
iterable of value-objects (list, tuple, …)- implicit iTree-objects created
- itertree.iTree.extendleft()
Multy item append on left hand-side (at the beginning) of the ´iTree´.
The operation is slower than ´extend()´ because it requires a reordering of all items in the iTree.
Note
The order of extended items is kept in the operation. It’s comparable with: ´[1,2,3]+[4,5,6]=[1,2,3,4,5,6]´ but the result is not a new instance, self is kept.
Note
In case the to be extended items have already a parent an implicit copy will be made. We do this because the internal copy can be created more effective. We accept also iTree-objects as extend_items parameter and the children which have a parent will be automatically copied to be integrated in this second tree. We have the same situation with a filtered iterator which might be used to extend this iTree too.
- Parameters:
items (Iterable) –
iterable-object that contains iTree-objects as items it can be:
iterator or generator of iTree-objects (using next)
iTree-object (children will be copied and extended in this tree
iterable of iTree-objects (list, tuple, …)
argument list for iTree-instance ( ´__init__()´ ) (created by ´get_init_args()´ or ´get_init_args_deep()´ )
iterator or generator of value-objects (using next) - implicit iTree-objects created
iterable of value-objects (list, tuple, …)- implicit iTree-objects created
- itertree.iTree.insert()
Insert an item before a given target-position. The insertion works like in lists.
The insertion operation is slower as the append operations.
If target=None is given the operation inserts in the last position (== append()).
- Except:
In case iTree-object has already a parent a RecursionError will be raised Other exceptions might come up in case the iTree is protected (tree read-only mode).
- Parameters:
target (Union[Integer,tuple,iTree,None]) –
target position definition; target must target a single/unique item! Possible targets:
index - absolute target index integer, negative values supported too (count from the end).
key - key-tuple (family_tag, family_index) pair
item - iTree-item that is already a children (future successor)
None - if None is given we will append the item in the last position of the ´iTree´-object
item (Union[iTree,object]) –
iTree-object to be inserted in the tree.
Warning
As in append() in case the given item-object is not a iTree-object the item is interpreted as a value and the iTree will be created implicit.
- Return type:
- Returns:
Delivers the inserted item itself (it might be useful for the user to get the updated information of the object).
- itertree.iTree.move()
Move this item in given target position (item will be positioned before the given target). The given target must be a unique item! If None is given the item will be moved in the last position of the iTree. If an ìTree`-object is given as target it must be a children of the same parent (sibling).
- Except:
LookupError in case the target is not found or not unique!
- Parameters:
target (Union[Integer,tuple,iTree,None]) –
target-object defining the replacement target; possible types are:
index - absolute target index integer, negative values supported too (count from the end).
key - key-tuple (family_tag, family_index) pair
item - iTree-item that is already a children (future successor)
None - if None is given we will move the item to the last position in the ´iTree´-object
- Returns:
self (with updated indexes)
- itertree.iTree.rename()
give the item a new family tag
The renaming of the item implies a reordering of the items in the tree because the family order depends on the global/absolute order of items.
- Parameters:
new_tag (Hashable) – new tag (any kind of hashable object)
- Return type:
- Returns:
Delivers the renamed item itself (it might be useful for the user to get the updated information of the object).
- itertree.iTree.pop()
pop the item out of the tree, if no key is given the last item will be popped out
We do not have the method popleft because pop(0) does the same.
- Parameters:
target (Union[int,tuple,Hashable,Iterable,slice,iTree]) –
target of popped item(s):
index - absolute target index integer (fastest operation)
key - key tuple (family_tag, family_index)
tag - Tag(family_tag) object targeting a whole family
target-list - absolute indexes or keys to be replaced (indexes and keys can be mixed)
index-slice - slice of absolute indexes
key-slice - tuple of (family_tag, family_index_slice)
itree_filter - method (callable) for filtering the children of the object
- Returns:
popped out item(s) (parent will be set to None). In case multiple items are removed an iterator over the removed items is given.
iTree other structure related commands
- itertree.iTree.__setitem__()
Replace an item with the given new item given in the value-parameter. The method handles also multiple replaces (rearrangements) like:
>>> mytree[1],mytree[0]=mytree[0],mytree[1]
Warning
Because of the parent only principle in rearrangements operations an implicit copy might be created.
Note
Linked items cannot be changed. If changes are required The user must change the link source tree items and afterwards actively rerun load_links() to reload the linked tree.
- Except:
In case the target is not found or the iTree is protected (read-only tree).
- Parameters:
target –
target object defining the replacement target; possible types are:
index - absolute target index integer (fastest operation)
key - key tuple (family_tag, family_index)
tag - Tag(family_tag) object targeting a whole family
target-list - absolute indexes or keys to be replaced (indexes and keys can be mixed)
index slice - slice of absolute indexes
key slice - tuple: (family_tag, family_index_slice)
For multi targets the given value must have a matching structure (item list with same length).
We have two special targets which are used for placing/replacing single items in the iTree:
Ellipsis … - new_items tag-family will be deleted and the new-item is placed in families first item position
items_tag - new_items tag-family will be delted and the new-item is placed in families last item position
If those two special targets are used and the new-items family does not exist yet, the method will just append the new item, no exception will be raised.
value – iTree object that should replace the target or in case of multi targets a tuple of items that should be used for replacements
- Returns:
value added items (only for internal usage)
- itertree.iTree.__delitem__()
The function deletes the targeted item in the tree.
- Except:
In case the target is not found or the iTree is protected (read-only tree).
- Parameters:
target (Union[int,tuple,Hashable,Iterable,slice]) –
target object defining the replacement target; possible types are:
index - absolute target index integer (fastest operation)
key - key tuple (family_tag, family_index)
tag - Tag(family_tag) object targeting a whole family
target-list - absolute indexes or keys to be replaced (indexes and keys can be mixed)
index-slice - slice of absolute indexes
key-slice - tuple of (family_tag, family_index_slice)
itree_filter - method (callable) for filtering the children of the object
- Returns:
deleted item
- itertree.iTree.clear()
deletes all children and the value!
All flags stay unchanged, except the load_links flag!
- Parameters:
keep_value (bool) –
True - value is not deleted
False - value will be replaced with NoValue
local_only (bool) –
True - clear only the local items
False - clear whole object (The object is reset to the no links loaded state and locals are deleted)
- itertree.iTree.copy()
create a copy of this item
The difference in between copy() and deepcopy() for iTree is just that we do in deepcopy() a deepcopy of all value items. In copy() we just copy the value object not the items inside, the pointers to the original objects are kept (for immutable objects there is no difference).
- Returns:
copied iTree object
- itertree.iTree.copy_keep_value()
Create a copy of this item.
The difference in between normal copy() and this method is that the value objects are completely untouched in this operation (for immutable objects there is no difference in between the two copy operations).
- Returns:
copied iTree object
- itertree.iTree.deepcopy()
create a deepcopy of this item
The difference in between copy() and deepcopy() for iTree is just that we do in deepcopy() a deepcopy of all value items. In copy() we just copy the value object not the items inside, the pointers to the original objects are kept (for immutable objects there is no difference).
- Returns:
deep copied new iTree object
The copy operations are automatically in-depth operations this means the items in the subtree will be copied too. This is required because of the one parent only principle. The available copy operations making a difference in the treatment of the itree.value-object:
copy() - creates a top-level copy of the value object
copy_keep_values() - copies just the iTree object but keep the value
deepcopy() - creates a deepcopy of the value object
The methods of the copy package use the same functionalities copy.copy(itree) ~ itree.copy() and copy.deepcopy(itree) ~ itree.deepcopy().
>>> import copy
>>> itree = iTree('root',value={'a':[1,2,3]})
>>> copied_itree=itree.copy()
>>> iTree(itree.tag,value=copy.copy(itree.value)) # root only copy (subtree eliminated)
iTree('root', value={'a': [1, 2, 3]})
>>> copied_itree.value is itree.value
False
>>> copied_itree.value['a'] is itree.value['a']
True
>>> deepcopied_itree=itree.deepcopy() # Inner values objects will be copied too
>>> deepcopied_itree_extern=iTree(itree.tag,value=copy.deepcopy(itree.value))
>>> deepcopied_itree.value is itree.value
False
>>> deepcopied_itree.value['a'] is itree.value['a']
False
>>> itree_only_copy=itree.copy_keep_value() # values will be taken over without copy
>>> itree_only_copy_extern=iTree(itree.tag,value=itree.value)
>>> itree_only_copy.value is itree.value
True
Some of the structural manipulation commands can be utilized also as an in-depth variant which will run over the nested iTree-structure. Use the helper class .deep for this propose.
- itertree.iTree.rotate()
Rotate children of the iTree-object n times (n positions) (rotate 1 times means move last item to first position)
If no parameter is given we rotate by one position only.
The rotation can be made in negative direction too (give negative numbers).
In case zero is given the operation is neutral and nothing will be changed.
Note
There is no in-depth counterpart of this method available.
- Parameters:
n (integer) – number of positions the items should be rotated
- itertree.iTree.reverse()
Reverse the order of all children in the iTree.
If you do not want to change the object itself (in place operation) you might use the iterator reversed() instead.
- itertree.iTree.deep.reverse()
coded in helper-class:
- itertree.itree_indepth._iTreeIndepthTree.reverse()
Call via iTree().deep.reverse()
In-depth reverse of the order of all children in the iTree. Same as method reverse() but this is the in-depth version of the method. This method dives deeper and the sub-children, sub-sub-children, … orders are reversed too.
Note
The implementation of this method is recursive for deep trees recursion limit might be reached.
- itertree.iTree.sort()
Sorting operation -> same behavior as sort of lists (parameter description is taken from list documentation).
Note
This is an “in place” operation which changes the content of the object the build-in sorted() might be use instead (if the original object should not be changed):
>>> a=iTree(subtree=[iTree(3),iTree(2),iTree(4),iTree(1)]) >>> a.render() iTree() > iTree(3) > iTree(2) > iTree(4) > iTree(1) >>> b=iTree(subtree=(a[i] for i in sorted(a.keys()))) iTree() > iTree(1) > iTree(2) > iTree(3) > iTree(4)
Internally in this operation a copied sorted list is created, and afterwards the whole structure is cleared and rebuild based on the sorted list.
The default-operation is to the sort based on the list of keys (tag-family, family_index) pair of the items. The base of the sorting can be modified by changing the target_type parameter.
- Parameters:
key – specifies a function of one argument that is used to extract a comparison key from each list element (for example, key=str.lower). The key corresponding to each item in the list is calculated once and then used for the entire sorting process. The default value of None means that list items are sorted directly without calculating a separate key value.
reverse – is a boolean value. If set to True, then the list elements are sorted as if each comparison were reversed.
- itertree.iTree.deep.sort()
coded in helper-class:
- itertree.itree_indepth._iTreeIndepthTree.sort()
Call via iTree().deep.sort()
sort operation running also over the deeper levels of the tree -> same behavior as sort of lists (parameter description is taken from list documentation)
In this operation internally a copied sorted list is created, the structure is cleared and rebuild based on the sorted list. The default-operation is to the sort based on the list of keys (tag-family.family_index) pair of the items. This might be modified by changing the target_type.
Warning
In case of really deep iTree`s (depth >100) the sorting might take a lot of time. We made a test with an `iTree containing ~2500 items and a depth of 9000. Result was: itree.all.sort() time: 83.772834 s (Python 3.9).
Note
The implementation of this method is recursive for deep trees recursion limit might be reached.
- Parameters:
key – specifies a function of one argument that is used to extract a comparison key from each list element (for example, key=str.lower). The key corresponding to each item in the list is calculated once and then used for the entire sorting process. The default value of None means that list items are sorted directly without calculating a separate key value.
reverse – is a boolean value. If set to True, then the list elements are sorted as if each comparison were reversed.
Additionally we support following rearrangement functions:
>>> root[0], root[1], root[2] = root[2], root[0], root[1]
>>> root[0:3] = root[2], root[0], root[1]
Traceback (most recent call last):
File "E:\projects\privat\itertree\src\itertree\examples\itree_docu_examples.py", line 125, in exec_and_print
result = eval(command)
File "<string>", line 1
root[0:3] = root[2], root[0], root[1]
^
SyntaxError: invalid syntax
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "E:\projects\privat\itertree\src\itertree\examples\itree_docu_examples.py", line 130, in exec_and_print
exec(command)
File "<string>", line 1, in <module>
File "E:\projects\privat\itertree\src\itertree\itree_main.py", line 1441, in __setitem__
return [it_setitem(old_items[i].idx, new) for i, new in enumerate(value)]
File "E:\projects\privat\itertree\src\itertree\itree_main.py", line 1441, in <listcomp>
return [it_setitem(old_items[i].idx, new) for i, new in enumerate(value)]
File "E:\projects\privat\itertree\src\itertree\itree_main.py", line 1473, in __setitem__
old_item_idx = family[0].idx
IndexError: list index out of range
>>> root[2], root[0], root[1] = root[0:3]
There might be cases where those in-place rearrangements might not work (We have not tested all possible combinations here) and be aware that in this kind of operations it can be that there are implicit copies (same as itree.copy()) of the original object-instances created.
In the following pseudo mathematical operations the result will always be a new iTree instance. Flags are not considered in those operations. Addition and multiplication is not permutable because the first object gives the tag,value for the resulting object!
The addition of iTree’s is possible the result contains always the properties of the first added item and the children of the second added item are appended to the items of the fiorst one by creating a copy.
>>> a = iTree('a', value={'mykey': 1}, subtree=[iTree('a1'), iTree('a2')])
>>> b = iTree('b', subtree=[iTree('b1'), iTree('b2')])
>>> itree = a + b
>>> repr(itree) # repr() is required to get the un-shorten representation of iTree (str() shortens the subtree-parameter)
iTree('a', value={'mykey': 1}, subtree=[iTree('a1'), iTree('a2'), iTree('b1'), iTree('b2')])
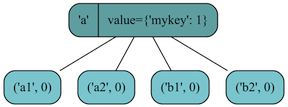
Figure showing the resulting iTree
Multiplication of a iTree is possible too the result is a list of iTree copies of the original one.
>>> itree_list = iTree('a') * 1000 # creates a list of 1000 copies of the original iTree
>>> itree_list[0]==itree_list[1] # items are equal
True
>>> itree_list[0] is itree_list[1] # but we have different instances
False
>>> root = iTree('root')
>>> root.extend(iTree('a') * 10000) # append all 10000 items as children to root
>>> len(root)
10000
In case two iTree-objects are multiplied in the result each children of first will be mixed with the children of the second in the scheme: child1_0,child2_0,child1_0,child2_1,…child1_1,child2_0,child1_1,child2_1…
>>> itree1=iTree('one',1,[iTree(1.0),iTree(1.1),iTree(1.2)])
>>> itree2=iTree('two',1,[iTree(2.0),iTree(2.1),iTree(2.2)])
>>> itree_mul=itree1*itree2
>>> itree_mul.render()
iTree('one', value=1)
> iTree(1.0)
> iTree(2.0)
> iTree(1.0)
> iTree(2.1)
> iTree(1.0)
> iTree(2.2)
> iTree(1.1)
> iTree(2.0)
> iTree(1.1)
> iTree(2.1)
> iTree(1.1)
> iTree(2.2)
> iTree(1.2)
> iTree(2.0)
> iTree(1.2)
> iTree(2.1)
> iTree(1.2)
> iTree(2.2)

Figure showing the resulting iTree after multiplication
The subtraction of two iTrees is supported too. The base of operation is the tag_idx of the items. Items with same tag_idx are eliminated (only in case they have same value too). With different values we try to calculate the the difference of the value objects if this is not possible the value will kept unchanged (value of the minuend is kept).
>>> itree1=iTree('one',1,[iTree('a',1.0),iTree('a',1.1),iTree('a','str')])
>>> itree1[0]-itree1[1] # same tage different value -> diff of value is calculated (if possible)
iTree(value=-0.10000000000000009)
>>> itree1[0]-itree1[2] # same tage different value -> diff not possible minuend is kept
iTree(value=1.0)
>>> sub_tree=itree1-itree1 # minus same object
>>> sub_tree.tag # tag eliminated
<class 'itertree.itree_helpers.NoTag'>
>>> sub_tree.value # value eliminated
<class 'itertree.itree_helpers.NoValue'>
>>> sub_tree.render() # subtree eliminated
iTree()
Subtraction of same iTree delivers an empty iTree object (tag=NoTag; value=NoValue).
Item Access
In this chapter we will dive in the “magic” of the iTree.get object.
The user can choose in between the common and the specific target access. The common access is more flexible related to the possibility of giving mixed target_paths and it is a bit more “lazy”. The specific access should be used if the quickest possible access is required (depending on the given target type it is ~2-6 times quicker compared to the common access). And it can be that the specific access is needed because of conflicting target content (e.g. if an integer tag is used in iTree, it cannot be reached via common access because the target will be interpreted as an absolute index access (higher priority the tag access))
Note
The common target access is also used when ever a item must be targeted in other functionalities like move() or insert()!
For common target access we have the following methods:
- itertree.iTree.__getitem__()
Main common get method for children (first level items).
In case the given targets is a absolute index or a key (tag,family-index) pair the method will deliver a unique item back. This operation is prioritized over the other operations.
For all other targets the method will deliver a list with the targeted items as result.
In some cases an empty list might be delivered and no exception might be raised (e.g. filter query delivers no match).
In case user likes to have other return-types he might check the other available get methods ( get(), get.single(), get.iter()) or he might also use the itertree helper method getter_to_list() to convert any of the possible results into a list.
- Except:
In case of no match (even if a part is not matching (e.g. one index in an index-list) the method will raise a KeyError (no matching target given); IndexError (no matching index given) or ValueError (no valid type of target given).
- Parameters:
target (Union[int,tuple,list,slice]) –
target object targeting a child or multiple children in the ´iTree´. Possible types are:
index - absolute target index integer (fastest operation)
key - key tuple (family_tag, family_index)
index-slice - slice of absolute indexes
key-index-slice - tuple of (family_tag, family_index_slice)
target-list - absolute indexes or keys to be replaced (indexes and keys can be mixed)
key-index-list - tuple of (family_tag, family_index_list)
tag - family_tag object targeting a whole family
tag-set - a set of family-tags targeting the items of multiple families
itree_filter - method (callable) for filtering the children of the object
all-children - if build-in iter or …`(Ellipsis) is given a list of all children will be given (same like list(itree.__iter__()))
- Return type:
Union[iTree,list]
- Returns:
Target was index or key -> one iTree item will be given; for all other targets a list will be delivered.
- itertree.iTree.get()
coded in helper-class:
- itertree.itree_getitem._iTreeGetitem.__call__()
Call via iTree().get()
Main get method for items that supports in-depth level-wise access too.
If only one parameter is given get behaves like __getitem__() except that a default parameter can be given so that it will be delivered (the normal method would raise an exception in this case). In case no default is given the exception will be raised too.
Warning
The default parameter must be given as a keyword argument only e.g.:get(1,default=None). All unnamed arguments given will always be interpreted as a target definitions!
In case the method got more than one unnamed argument an in-depth target access will be performed. Each parameter will target in this case the next nested level of the tree.
The method can be seen as a replacement of the operation self[target_deep[0]][target_deep[1]]…[target_deep[-1]]
Note
But be aware that the results in the different levels might not be unique and therefore in detail the method will behave different as the simple direct targeting (which will raise an exception in this case). This method will create an iterator of all (branched) findings in the deepest targeted level instead.
In this case the method will deliver an iterator of all the findings in the mostlowest level targeted. The iterator is always flatten even that in higher levels we might have multiple findings.
E.g. the user might have build a tree like this:
>>> root_tree.render() iTree('root', value=0) > iTree('sub', value=1) . > iTree('subsub', value=5) > iTree('sub1', value=2) . > iTree('subsub', value=6) > iTree('sub2', value=3) . > iTree('subsub', value=7) > iTree('sub', value=4) . > iTree('subsub', value=8) >>> get('sub','subsub') [iTree('subsub', value=5), iTree('subsub', value=8)]
The reason for this result is that the first match is not unique and so the sub-items in the target levels are combined into on flatten result.
The return of this method can be the following:
Pure index and key list is given -> single target -> iTree object should be delivered
list of all found items
No match found an KeyError or IndexError will be raised
- Except:
In case no matching item is found a KeyError or IndexError is raised. In case of invalid targets TypeError or ValueError will be raised.
- Parameters:
target (Union[int,tuple,list,slice]) –
level 0 target object targeting a child or multiple children in the ´iTree´. Possible types are:
index - absolute target index integer (fastest operation)
key - key tuple (family_tag, family_index)
index-slice - slice of absolute indexes
key-index-slice - tuple of (family_tag, family_index_slice)
target-list - absolute indexes or keys to be replaced (indexes and keys can be mixed)
key-index-list - tuple of (family_tag, family_index_list)
tag - family_tag object targeting a whole family
tag-set - a set of family-tags targeting the items of multiple families
itree_filter - method (callable) for filtering the children of the object
all-children - if build-in iter() or … (Ellipsis) is given a list of all children will be given (same result as list(itree.__iter__()) )
*target_path –
in-depth targets iterable of targets for the different levels 1-n The supported targets in each level are (same like __getitem__():
index - absolute target index integer (fastest operation)
key - key tuple (family_tag, family_index)
index-slice - slice of absolute indexes
key-index-slice - tuple of (family_tag, family_index_slice)
target-list - absolute indexes or keys to be replaced (indexes and keys can be mixed)
key-index-list - tuple of (family_tag, family_index_list)
tag - family_tag object targeting a whole family
tag-set - a set of family-tags targeting the items of multiple families
itree_filter - method (callable) for filtering the children of the object
all-children - if build-in iter() or … (Ellipsis) is given a list of all children will be given (same result as list(itree.__iter__()) )
default – The parameter must be given as keyword parameter! The object given will be delievred in case of issues. If the parameter is not set (==Exception) exceptions will be raised in case of issues.
- Return type:
Union[iTree,list]
- Returns:
iTree object or list of objects
- itertree.iTree.get.single()
coded in helper-class:
- itertree.itree_getitem._iTreeGetitem.single()
Call via iTree().get.single()
In general the methods does same like the “normal” get() but the method delivers only single (unique) results. In case get() delivers multiple items this method will raise an Exception or delivers the default value (if defined).
Note
In case the match contains a list with only one element the result is unique too. The method will unpack the unique item from the iterable and return it in this case.
- Except:
If default parameter is not set an KeyError or IndexError will be raised. If result is not unique a ValueError will be raised
- Parameters:
target (Union[int,tuple,list,slice]) –
level 0 target object targeting a child or multiple children in the ´iTree´. Possible types are:
index - absolute target index integer (fastest operation)
key - key tuple (family_tag, family_index)
index-slice - slice of absolute indexes
key-index-slice - tuple of (family_tag, family_index_slice)
target-list - absolute indexes or keys to be replaced (indexes and keys can be mixed)
key-index-list - tuple of (family_tag, family_index_list)
tag - family_tag object targeting a whole family
tag-set - a set of family-tags targeting the items of multiple families
itree_filter - method (callable) for filtering the children of the object
all-children - if build-in iter() or … (Ellipsis) is given a list of all children will be given (same result as list(itree.__iter__()) )
*target_path –
in-depth targets iterable of targets for the different levels 1-n The supported targets in each level are (same like __getitem__():
index - absolute target index integer (fastest operation)
key - key tuple (family_tag, family_index)
index-slice - slice of absolute indexes
key-index-slice - tuple of (family_tag, family_index_slice)
target-list - absolute indexes or keys to be replaced (indexes and keys can be mixed)
key-index-list - tuple of (family_tag, family_index_list)
tag - family_tag object targeting a whole family
tag-set - a set of family-tags targeting the items of multiple families
itree_filter - method (callable) for filtering the children of the object
all-children - if build-in iter() or … (Ellipsis) is given a list of all children will be given (same result as list(itree.__iter__()) )
default (object) – If parameter is set in case of no match the default object will be delivered. If parameter is not set an Exception will be raised
- Return type:
Union[iTree,object]
- Returns:
found single item or default (in case default is set)
- itertree.iTree.get.iter()
coded in helper-class:
- itertree.itree_getitem._iTreeGetitem.iter()
Method call via iTree().get.iter()
In general the methods does same like the “normal” get() but the method delivers an iterator results. In case get() delivers a single items this method will deliver [item].
If no match is found will be delivered the default value (if defined).
If no target is given [self] will be delivered.
Warning
It can be that an empty iterator is delivered and no Exception is raised in this case!
Note
In case the target item should be iterated afterwards this method is recommended because some operations are quicker then the standard get().
- Except:
If default parameter is not set an KeyError or IndexError will be raised. If result is not unique a ValueError will be raised.
- Parameters:
target (Union[int,tuple,list,slice]) –
level 0 target object targeting a child or multiple children in the ´iTree´. Possible types are:
index - absolute target index integer (fastest operation)
key - key tuple (family_tag, family_index)
index-slice - slice of absolute indexes
key-index-slice - tuple of (family_tag, family_index_slice)
target-list - absolute indexes or keys to be replaced (indexes and keys can be mixed)
key-index-list - tuple of (family_tag, family_index_list)
tag - family_tag object targeting a whole family
tag-set - a set of family-tags targeting the items of multiple families
itree_filter - method (callable) for filtering the children of the object
all-children - if build-in iter() or … (Ellipsis) is given a list of all children will be given (same result as list(itree.__iter__()) )
*target_path –
in-depth targets iterable of targets for the different levels 1-n The supported targets in each level are (same like __getitem__():
index - absolute target index integer (fastest operation)
key - key tuple (family_tag, family_index)
index-slice - slice of absolute indexes
key-index-slice - tuple of (family_tag, family_index_slice)
target-list - absolute indexes or keys to be replaced (indexes and keys can be mixed)
key-index-list - tuple of (family_tag, family_index_list)
tag - family_tag object targeting a whole family
tag-set - a set of family-tags targeting the items of multiple families
itree_filter - method (callable) for filtering the children of the object
all-children - if build-in iter() or … (Ellipsis) is given a list of all children will be given (same result as list(itree.__iter__()) )
default (object) – If parameter is set in case of no match the default object will be delivered. If parameter is not set an Exception will be raised
- Return type:
Union[list,blist,Iterator]
- Returns:
An iterator or a list with a single item will be delivered
The first method __getitem__() targets first level only (access via “brackets-operation” itree[]). All other methods are capable to target via in-depth access (realized via multiple parameters that can be given to the method).
Warning
The usage of target_paths are just supported by the get-subclass. The following methods supporting target-paths containing mixed target-items (different types):
get()
get.single()
get.iter()
The other methods in get-subclass support only target-paths with unique targets (matching to the specific method).
The method __getitem__() does not support target-paths it just takes targets targeting the level 1 children only!
The return type of the common access functions __getitem__()`and `get() depends on the given target-type:
absolute index, key (family tag-index pair) -> unique iTree-item will be delivered
all other targets (multi target operations) -> list of matching items (in some case a blist object might be delivered)
The get.single() method delivers only single iTree-objects and get.iter() delivers an iterator of the matches found.
For the specific access the following methods are available:
- itertree.iTree.get.by_idx()
coded in helper-class:
- itertree.itree_getitem._iTreeGetitem.by_idx()
Call via iTree().get.by_idx()
Get items by absolute index.
This is the quickest getter function we have in iTree . As parameters the user can give just integers.
For in-depth operations the user can give an index-path (pointer).
- Parameters:
idx (int) – first item index
*idx_path –
in case we have a in-depth operation we use index path and first given idx will be integrated in the operation (give level 1- n index)
default (object) – This is a named parameter only! If default is given the default objet will be returned in case of internal exceptions. If default is Exception an exception is raised
- Return type:
- Returns:
target item
- itertree.iTree.get.by_idx_slice()
coded in helper-class:
- itertree.itree_getitem._iTreeGetitem.by_idx_slice()
Call via iTree().get.by_idx_slice()
Get items by absolute index slice.
For in-depth operations the user can give multiple parameters (a slices per level). The findings are combined to a final flatten list.
The operation can be mixed with normal indexes.
Note
If the user likes to target all items in a level he can give the slice(None) object which will iterate over all children of the level
To target a single item slice(n,n+1) must be given.
- Parameters:
idx_slice (slice) – absolute index slice for level 0 access (a slice object must be given!)
*idx_path –
Give multiple parameters (one slice per level)
default (object) – This is a named parameter only! If default is given the default objet will be returned in case of internal exceptions. If default is Exception an exception is raised
- Return type:
list
- Returns:
list of target iTree-items
- itertree.iTree.get.by_idx_list()
coded in helper-class:
- itertree.itree_getitem._iTreeGetitem.by_idx_list()
Call via iTree().get.by_idx_list()
Get items via absolute index lists.
For in-depth operations the user can multiple parameters (one parameter per level) each parameter must be an absolute index list.The findings are combined to a final flatten list.
Note
The user can give … (Ellipsis) to target all children in a specific level
- Parameters:
idx_list (list) – list of absolute indexes targeting level 0
*idx_list_path –
Give multiple parameters (one index list per level)
default (object) – This is a named parameter only! If default is given the default objet will be returned in case of internal exceptions. If default is Exception an exception is raised
- Return type:
list
- Returns:
list of targeted iTree-items
- itertree.iTree.get.by_tag_idx()
coded in helper-class:
- itertree.itree_getitem._iTreeGetitem.by_tag_idx()
Call via iTree().get.by_tag_idx()
Get items by tag-idx-key (tag,family-index) tuple.
This is the quickest getter function available for tag-idx access (comparable to keys in dicts) we have in iTree. The parameters must be (tag, family-idx) tuples.
For in-depth operations the user can give a tag_idx_path. In this case the methods dives into the tree and extracts the matching items in the different levels
- Parameters:
tag_idx (tuple) – level one tag-idx-key
*idx_path –
In-depth parameters each additional parameter must be a tag-idx-key target the item in the specific level
default (object) – This is a named parameter only! If default is given the default objet will be returned in case of internal exceptions. If default is Exception an exception is raised
- Return type:
- Returns:
targeted item
- itertree.iTree.get.by_tag_idx_slice()
coded in helper-class:
- itertree.itree_getitem._iTreeGetitem.by_tag_idx_slice()
Call via iTree().get.by_tag_idx_slice()
Get items via tag_idx_key containing a slice in the family index tuple(tag,family-index-slice). The user must give here a slice object.
For in-depth operation additional tag_idx_keys containing slices can be added. To target a whole family the user may give the slice(None). The results in the different levels are merged to a flatten list containing all matches in the highest targeted level.
- Parameters:
tag_idx_slice (tuple) – tuple of tag and family-index-slice
*tag_idx_path –
Give additional tag-idx-slices per target level in-depth of the iTree
default (object) – This is a named parameter only! If default is given the default objet will be returned in case of internal exceptions. If default is Exception an exception is raised
- Return type:
list
- Returns:
list of targeted iTree-items
- itertree.iTree.get.by_tag_idx_list()
coded in helper-class:
- itertree.itree_getitem._iTreeGetitem.by_tag_idx_list()
Call via iTree().get.by_tag_idx_list()
Get items by giving a tag-family-index-list tuple.
For in-depth operation the user can add more tag-family-index-list tuples as additional parameters targeting the in-depth levels of the iTree object.
To target all family items of a specific level the ,,,-object`(Ellipsis) can be placed as parameter.
- Parameters:
tag_idx_list (tuple) – tuple of tag and a list of family-indexes (e.g. (‘mytag’,[1,2,3]))
*tag_idx_list_path –
Additional parameters each containing a tuple with tag and a list of indexes for each in-depth level of the iTree
default (object) – This is a named parameter only! If default is given the default objet will be returned in case of internal exceptions. If default is Exception an exception is raised
- Return type:
list
- Returns:
list of targeted iTree-items
- itertree.iTree.get.by_tag()
coded in helper-class:
- itertree.itree_getitem._iTreeGetitem.by_tag()
Call via iTree().get.by_tag()
Get family items by given tag.
This is the quickest getter function for families.
For in-depth operation the user can give as additional parameters more tags (one tag per level). The findings are cumulated and delivered as a flattened item list.
- Parameters:
tag (hashable) – Family tag targeting all items inside the family
*tag_path –
hashable tags targeting the deeper levels of iTree
default (object) – This is a named parameter only! If default is given the default objet will be returned in case of internal exceptions. If default is Exception an exception is raised
- Return type:
list
- Returns:
list of targeted iTree-items
- itertree.iTree.get.by_tags()
coded in helper-class:
- itertree.itree_getitem._iTreeGetitem.by_tags()
Call via iTree().get.by_tags()
Here the user gives an iterable of tags for the to be targeted families (multiple families). The targeted items are combined in one list.
For in-depth operation the user can give additional parameters containing tag-iterables per target levels. The result is cumulated and delivers all found items in the deepest targeted level.
The user might give also single tags (but it’s recommended to put them in a list -> see the warning).
Warning
Tuples are interpreted as iterables in this case! If the user likes to target a single tag which is a tuple-object he must give an additional iteration level (e.g. tag=(1,2) tags([(1,2)] must be given to target the tag-family (1,2)).
- Parameters:
tags (Iterable) – Iterable of family tags
*tags_path –
Additional family-tag iterables for deeper levels of teh iTree
default (object) – This is a named parameter only! If default is given the default objet will be returned in case of internal exceptions. If default is Exception an exception is raised
- Return type:
list
- Returns:
list of target items
- itertree.iTree.get.by_level_filter()
coded in helper-class:
- itertree.itree_getitem._iTreeGetitem.by_level_filter()
Call via iTree().get.by_level_filters()
Get items by level-filters.
For in-depth operation additional parameters can be given each is a level-filter for the next level.
In case the build-in iter-method is given (without parameters) all items in the level will be considered (no filtering). The level filtering is always a hierarchical filtering.
- Parameters:
filter_method (Method) – filter_method analysis the itree-items and delivers True for a match and False for no match (filtered out)
*filter_method_path –
Additional parameters for filter_methods for the deeper levels of the iTree.
default (object) – This is a named parameter only! If default is given the default objet will be returned in case of internal exceptions. If default is Exception an exception is raised
- Return type:
list
- Returns:
list of filtered iTree-items found in the deepest targeted level
Target description
Beside the construction of the object the access to it’s items is the second core-functionality for a tree object.
In iTree this is one of the most complex functionalities available. The reason is the wide range of different possible targets that are supported. It’s recommended that the user reads the following explanations and examples carefully to understand the full range of functionalities available related to the access of children stored in iTree.
But even for less experienced users the easy access via itree[index] (list like counterpart) or itree[tag_idx_key] (dict-like counterpart) will work in most cases.
Lets build a small example iTree-object and let’s see with which target definitions we can access the children in this object:
>>> root = iTree('root')
>>> root += iTree('child', value=0)
>>> root += iTree('child', value=1)
>>> root += iTree('child', value=2)
>>> root += iTree('child', value=3)
>>> root += iTree('child', value=4)
>>> root += iTree(1, value=5)
>>> root += iTree(('child',1), value='tag conflict')
>>> # any hashable object can be used as tag!
>>> root += iTree((1, 2, 3), value=6) # any hashable object can be used as tag!
>>> root.render()
iTree('root')
> iTree('child', value=0)
> iTree('child', value=1)
> iTree('child', value=2)
> iTree('child', value=3)
> iTree('child', value=4)
> iTree(1, value=5)
> iTree(('child', 1), value='tag conflict')
> iTree((1, 2, 3), value=6)

Figure showing the resulting iTree
In the following examples have a special look on the result types delivered (single-targets -> iTree-child and multi-targets -> list of matching children in iTree-order):
Target via absolute index:
The absolute index is like the index in lists and targets the children counting from 0. And as in lists negative values are supported too (count index from the last index down).
This operation is the fastest way to target a item in iTree-objects.
This operation has highest priority in common access. It will “cover” the tag access to families (based on integer-type tags).
The specific access method get.by_idx() is faster and can be used too.
This is a single/unique target therefore it delivers directly the targeted iTree-child-object.
>>> # Common index access: >>> root[0] # absolute index access iTree('child', value=0) >>> root[-1] # absolute index access (negative values) iTree((1, 2, 3), value=6) >>> root[5] # This child is not targeted in the next step even that it's tag==1! iTree(1, value=5) >>> root[1] # The absolute index access has higher priority than access via tags iTree('child', value=1) >>> # Specific index access: >>> root.get.by_idx(0) # absolute index access iTree('child', value=0) >>> root.get.by_idx(-1) # absolute index access (negative values) iTree((1, 2, 3), value=6) >>> root.get.by_idx(5) # This child is not targeted in the next step even that it's tag==1! iTree(1, value=5) >>> root.get.by_idx(1) # The absolute index access has higher priority than access via tags iTree('child', value=1)
Target via absolute index-slice:
As in lists the slicing of the absolute index is supported too.
But the result is no more unique, therefore the operation will return a list or blist.
The specific access method for this target is get.by_idx_slice() but the method parameter(s) must be slice object(s).
>>> # Common index-slice access: >>> root[1:3] blist([iTree('child', value=1), iTree('child', value=2)]) >>> # Specific index-slice access: >>> root.get.by_idx_slice(slice(1,3)) blist([iTree('child', value=1), iTree('child', value=2)])
Target via absolute index-list:
We can target multiple children by giving a list of indexes. The resulting list represents the order of indexes the user gave.
Warning
Duplicated indexes will deliver duplicated items in the result. Especially in case of in-depth access this should be avoided, because the results can be very confusing.
No unique result, a list will be returned.
The specific access method for this target is get.by_idx_list().
>>> # Common index-list access: >>> root[[0, 2]] [iTree('child', value=0), iTree('child', value=2)] >>> # same as: >>> [root[0],root[2]] [iTree('child', value=0), iTree('child', value=2)] >>> root[[2, 0, 2]] # The target-order is kept (even multiple same items are kept) [iTree('child', value=2), iTree('child', value=0), iTree('child', value=2)] >>> # Specific index-list access: >>> root.get.by_idx_list([0, 2]) [iTree('child', value=0), iTree('child', value=2)]
Target via tag-idx (key):
This tag-idx-key (family-tag, family-index) is unique for any child. The second item in the tuple is the family-index. This gives the position of the child in the related tag-family-list (negative values supported too -> count from the end). A tag-idx-key is internally identified via the given tuple of length 2. (For downward compatibility the TagIdx-helper-object is still available and can be used for this case too).
This operation has highest priority and covers tag access to families based on tuples and this operation is the second fastest way (after absolute index access) to target a object in iTrees.
The key is unique therefore the operation delivers a single iTree-object.
The specific access method for this target is get.by_tag_idx().
>>> # Common tag-idx-key access (given as tuple) >>> # and how it must be used for targeting in other commands e.g. `insert()` or `move()`: >>> root[('child', 0)] iTree('child', value=0) >>> root['child', 0] # lazy way to give the tag-idx-key iTree('child', value=0) >>> root[('child', -1)] # negative family-index, is supported too iTree('child', value=4) >>> root[('child',1), 0] # This child is not targeted in the next step even that it's tag==('child',1)! iTree(('child', 1), value='tag conflict') >>> root[('child', 1)] # The key access has higher priority than access via tags iTree('child', value=1) >>> # Specific tag-idx access (must be given as tuple) >>> root.get.by_tag_idx(('child', 0)) # Give the tuple; multiple parameters would target in-depth! iTree('child', value=0)
Target via (family-tag, family-index-slice) - pair:
Slice operations on family_index is supported but the slice object must be given explicit slice(start,end,step).
Note
In this case we cannot use the slice definition via double dots like [0:3:2] . We must define a slice()-object.
Result is not unique a item therefore a list or blist with the selected items will be returned.
The specific access method for this target is get.by_tag_idx_slice().
>>> # Common tag-idx-slice access (given as tuple) >>> root[('child',slice(0,3,2))] blist([iTree('child', value=0), iTree('child', value=2)]) >>> root['child',slice(0,3,2)] # lazy input supported blist([iTree('child', value=0), iTree('child', value=2)]) >>> # Specific tag-idx-slice access (must be given as tuple) >>> root.get.by_tag_idx_slice(('child',slice(0,3,2))) blist([iTree('child', value=0), iTree('child', value=2)])
Target via (family-tag, family-index-list) - pair:
Giving a index list of family indexes to target the children is supported.
The order of the delivered items is the order of indexes given and duplicates are kept too.
Result is a list of matching children.
The specific access method for this target is get.by_tag_idx_list().
>>> # Common tag-idx-list access (given as tuple) >>> root[('child',[0,2])] [iTree('child', value=0), iTree('child', value=2)] >>> root[('child',[0,2])] # lazy input supported [iTree('child', value=0), iTree('child', value=2)] >>> # Specific tag-idx-list access (must be given as tuple) >>> root.get.by_tag_idx_list(('child',[0,2])) [iTree('child', value=0), iTree('child', value=2)]
Target a whole tag-family:
Here we target all items that have the same tag (same family).
As already shown this object has lower priority, in case of conflicts (with idx or tag_idx) the user should use the specific access method or he puts the tag as a single value in a set itree[{tag}] but the access is much slower as the specific one.
Result is a list with all children having the target tag (whole tag-family).
The specific access method for this target is get.by_tag().
>>> root['child'] # In case of no conflicts a given family tag delivers the family directly blist([iTree('child', value=0), iTree('child', value=1), iTree('child', value=2), iTree('child', value=3), iTree('child', value=4)]) >>> # specific tag-family access >>> root.get.by_tag('child') blist([iTree('child', value=0), iTree('child', value=1), iTree('child', value=2), iTree('child', value=3), iTree('child', value=4)]) >>> root.get.by_tag(('child',1)) # target ('child',1) tag-family with root[('child',1)] the tag-idx is targeted! [iTree(('child', 1), value='tag conflict')] >>> # The tag=('child',1) is a family tag not a tag-idx-key! >>> root.get.by_tag(1) # target again an item which cannot be reached via root[1] [iTree(1, value=5)] >>> root[{1}] # In case of conflicts the user can use a tag-set with one item too (slower as specific access) [iTree(1, value=5)] >>> # The tag=1 is a family tag not an absolute index!
Target multiple tag-families tag-families-set:
If a set of multiple tags is given the children of the different families are combined in the output list.
Result is a list with all children having the target tag that were targeted. The order of the items is the order of the families in the set.
The specific access method for this target is get.by_tags(). Different to the common access we can give here also lists or tuples as parameter(s) the order will be kept but duplicates will be delivered as given too.
>>> root[{(1,2,3),1,('child',1)}] # order of tags in the set is kept in the result [iTree(1, value=5), iTree((1, 2, 3), value=6), iTree(('child', 1), value='tag conflict')] >>> root[{1,('child',1),(1,2,3),}] [iTree(1, value=5), iTree((1, 2, 3), value=6), iTree(('child', 1), value='tag conflict')] >>> root.get.by_tags([1,('child',1),(1,2,3),]) # here the order of th tags in the list is kept; duplicates will be delivered too [iTree(1, value=5), iTree(('child', 1), value='tag conflict'), iTree((1, 2, 3), value=6)]
Target children via a filter-method:
A filter-method is a function that analysis the children object related to the properties, attributes, etc. and that generates at the end a True/False (match/ no match) return per item. By this the children are filtered and only the matching ones will be integrated into the result.
We have multiple items in the result a list will be returned.
The specific access method for this target is get.by_level_filter()
>>> # The following EXCEPTION is expected: >>> root[lambda i: i.value%2==0] # filters all children which contains an even value, but we have an exception: Traceback (most recent call last): ... TypeError: lambda: raised an exception in filter-calculation, the 6. child iTree(('child', 1), value='tag conflict') is incompatible with the calculation >>> root[lambda i: type(i.value) is int and i.value%2==0] # ensure that the filter-calculation matches to any child! [iTree('child', value=0), iTree('child', value=2), iTree('child', value=4), iTree((1, 2, 3), value=6)] >>> root[(lambda i: i.value==2)] # This filter targets in our case one value only [iTree('child', value=2)] >>> root.get.by_level_filter(lambda i: type(i.value) is int and i.value%2==0) # ensure that the filter-calculation matches to any child! [iTree('child', value=0), iTree('child', value=2), iTree('child', value=4), iTree((1, 2, 3), value=6)] >>> root.get.by_level_filter(lambda i: i.value==2) # This filter targets in our case one value only [iTree('child', value=2)]
Target all children via a build-in iter or … (Ellipsis):
The user can target all children of the iTree-object if he gives the ìter or … build-in function as a target.
This function may make no sense from the first view because it’s equivalent to the main children iterator __iter__(). But we will see that the option is very helpful in target_paths.
This results in multiple items and a list is returned.
>>> root[iter] # give build in iter to target all children blist([iTree('child', value=0), iTree('child', value=1), iTree('child', value=2), iTree('child', value=3), iTree('child', value=4), iTree(1, value=5), iTree(('child', 1), value='tag conflict'), iTree((1, 2, 3), value=6)]) >>> list(root) # is the recommended equivalent function for this but here we need must create the list explicit from the iterator [iTree('child', value=0), iTree('child', value=1), iTree('child', value=2), iTree('child', value=3), iTree('child', value=4), iTree(1, value=5), iTree(('child', 1), value='tag conflict'), iTree((1, 2, 3), value=6)] >>> root[(lambda i: True)] # Delivers also the same result but is much slower [iTree('child', value=0), iTree('child', value=1), iTree('child', value=2), iTree('child', value=3), iTree('child', value=4), iTree(1, value=5), iTree(('child', 1), value='tag conflict'), iTree((1, 2, 3), value=6)]
Use different targets to target children in the first level via a target-list:
In a target list (instead of a absolute index only list) the user can combine the different targets already explained (cumulate the targets).
The result is a flatten list that combines all those targeted children. The order of the children is defined by the order of given targets and duplicates will be kept!
Mixed target lists can only be used via common access methods.
>>> # Here we target absolute index, absolute index, tag-idx-key,family-set,filter >>> root[[0,1,('child', 1),{1},lambda i: type(i.value) is int and i.value>4]] # in result the iTree children order is kept and duplicates are deleted [iTree('child', value=0), iTree('child', value=1), iTree('child', value=1), iTree(1, value=5), iTree(1, value=5), iTree((1, 2, 3), value=6)] >>> root[[{1},('child', 1),lambda i: type(i.value) is int and i.value>4,0,1]] # same targets in other order delivers same result [iTree(1, value=5), iTree('child', value=1), iTree(1, value=5), iTree((1, 2, 3), value=6), iTree('child', value=0), iTree('child', value=1)]
Finally KeyError, IndexError, ValueError or TypeError Exceptions will be raced in case we have no match (output is shortened in these examples):
- ::
In-depth Item Access
In general all get methods can be used for in-depth access too (The only exception is the __getitem__()-method that targets first level only).
In the get-methods the levels are addressed by multiple parameters:
get(target_level1, target_level2, …,target_leveln).
To check the in-depth access we append our example with an item in level2 of the tree:
>>> root[0].append(iTree('sub_child',value=0)) # prepare one level deeper item
iTree('sub_child', value=0)

Figure shows the tree with additional level in first item
For sure the deeper levels can be accessed via multiple __getitem__() too. But in case of multiple matches the results can be very confusing.
Imagine in the first level you target a tag-family with multiple items the second index targets in this case the items in the delivered level1 list only and does not dive in the tree as the user might expect:
>>> root[0][0] # access nested (deeper) items
iTree('sub_child', value=0)
>>> root['child'][0] # If the result of first operation is not a single item this will deliver the first item in the result-list
iTree('child', value=0, subtree=[iTree('sub_child', value=0)])
>>> # See that the result is in the first and not in the second level of the iTree!!
To avoid such failures it’s recommended to use the more advanced in-depth get-methods. E.g: usage of get():
>>> root.get(0,0)
iTree('sub_child', value=0)
>>> root.get(0,('sub_child',0)) # access nested (deeper) items via target-path-list (mixed target types)
iTree('sub_child', value=0)
>>> target_path=[0,0]
>>> root.get(*target_path) # targets deep
iTree('sub_child', value=0)
>>> root.get(*[0,0]) # targets deep -> single item arguments given will deliver single item only
iTree('sub_child', value=0)
>>> # be CAREFUL because:
>>> root.get(*[0,0]) # gives empty list because target single item has no subtree (type cast to list)
iTree('sub_child', value=0)
>>> root.get(target_path) #target first level only (absolute index-list given)
[iTree('child', value=0, subtree=[iTree('sub_child', value=0)]), iTree('child', value=0, subtree=[iTree('sub_child', value=0)])]
>>> root.get([0,0]) #target first level only (absolute index-list given)
[iTree('child', value=0, subtree=[iTree('sub_child', value=0)]), iTree('child', value=0, subtree=[iTree('sub_child', value=0)])]
The functionality of get() is to handle multiple results in higher levels and combine them in an internal iterator. The result is at the end a flattended list that considers all findings in the final target level from all branches that were matching.
In case one level only is given the method behaves like __getitem__() except that in case of issues a default might be returned (if defined as named parameter).
The method get.single() enforces the delivery of unique items. The user can be sure that just a single item will be delivered. In case of multi-target parameters given the method analysis the result and shrink a list with a unique element to the element itself. If the list contains more items this is handled as no match and a ValueError will be raised (or default value will be delivered if defined).
The method get.iter() delivers always an iterator over the items targeted. In case of unique findings it delivers a list [unique_item] that is iterable and can be easy identified by a type check.
For the in-depth get-methods a level filter functionality is available. The user can define level filters by giving filtering methods for the different levels (see level-filtering).
>>> root.get(lambda i: i.value==0,lambda i: i.value==0) # level filtering
[iTree('sub_child', value=0)]
Comparing iTrees
In case iTree-items should be compared the difference in between the == operator and the is keyword should be understood. An ìTree object is equal ( == ) if the following statement delivers True :
>>> itree.tag and itree.data and all(sub_i==sub_o for sub_i,sub_o in zip(itree,other))
True
To check if the item is really the same (instance) the user must use is.
- itertree.iTree.__eq__()
compares if the tag, value and children content of another item matches with this item
Note
If you like to check if it is really the same object you should use ´is´ instead of ´==´ operator
- Parameters:
other – other iTree
- Returns:
boolean match result (True match/False no match)
- itertree.iTree.equal()
compares if the data content of another item matches with this item
- Parameters:
other – other iTree
check_coupled – check the couple object too? (Default False)
check_flags – check the flags of the objects? (Default False)
- Returns:
boolean match result (True match/False no match)
- itertree.iTree.__hash__()
The hash operation is available
- Returns:
integer hash
The explicit equal() method allows the check of additional properties (e.g. flags or the itree.coupled_object ), which are not considered in the normal __eq__() method.
The difference inbetween == and is is also important in case of the ìn operation where the operation == is used. Same for the index() and deep.index() method. The index() function behaves here like in lists and the start parameter can be used to target multiple searches.
To get the index of a specific item it is recommended just to use the ìTree property itree.idx or itree.idx_path which delivers the absolute index/index-path of the specific item directly.
- property iTree.idx
Index of this object in the iTree (related to the absolute order)
Method is very important for internal functionalities
Note
In general the item index is cached but in case of deleted items or reorder operations the cache might be outdated. In this case the index update based on a search might take longer.
- Return type:
Union[int, None]
- Returns:
unsigned integer representing the index (related to absolute order of iTree)
- property iTree.idx_path
delivers a list of absolute indexes from the root to this item
For items with no parent (root_item) an empty tuple will be delivered
Note
We deliver here a tuple because it might be helpful if the object is hashable (usage as a dict key)
- Return type:
tuple
- Returns:
tuple of index integers (here we do not deliver an iterator!)
Methods checking if a item is a child of the iTree-object:
- itertree.iTree.__contains__()
Checks if an ´iTree´ object is part of the ´iTree´ for comparison == -> ´__eq__()´ is used. For finding a specific object use ´is_parent()´ or ‘is_in()` instead.
In case no ´iTree´ object is given the function uses ´__getitem__´ to check if matching item(s) exists.
Note
There is no coresponding in-depth function available the user can easy search via: >>> # Let itree be the iTree object the target should be searched in >>> any(tag == i.tag for i in itree.deep) >>> any(searchkey == i[0][-1] for i in itree.deep.tag_idx_paths()) >>> s=len(index_list) >>> any(len(i[0])>s and index_list == i[0][(-s+1):] for i in itree.deep.idx_paths())
- Parameters:
target – iTree object searched for or a target used by ´__getitem__()´ method
- Returns:
True - matching child is found
False - no matching item found
- itertree.iTree.deep.__contains__()
coded in helper-class:
- itertree.itree_indepth._iTreeIndepthTree.__contains__()
Call via x in iTree().deep
Checks if given ´iTree´ is child or sub-child of the ´iTree´ (inside). For comparison == -> ´__eq__()´ is used. For finding the exact object instance use ´is_in()´ instead.
- Parameters:
item (iTree) – iTree object to be searched for
- Return type:
bool
- Returns:
True - matching child is found
False - no matching item found
- itertree.iTree.is_in()
Checks if the given object is child of the iTree. Different to ´__contains__()´ we check here for the instance (specific) object (is) and not based on ´__eq__()´.
- Parameters:
item – iTree object to be searched for
- Returns:
True - matching child is found
False - no matching item found
- itertree.iTree.deep.is_in()
coded in helper-class:
- itertree.itree_indepth._iTreeIndepthTree.is_in()
Call via iTree().deep.is_in()
Checks if the given object is in thee iTree. Different to ´__contains__()´ we check here for the instance (specific) object (is) and not based on ´__eq__()´.
- Parameters:
item (iTree) – iTree object to be searched for
- Return type:
bool
- Returns:
True - matching child is found
False - no matching item found
- itertree.iTree.index()
The index method allows to search for the absolute index of a matching item in the iTree. The item must be a iTree object and the index will deliver the first match. The comparison is made via == operator.
If item is not found a IndexError will be raised
Note
To get the index of a specific item instance the .idx- property should be used.
- Parameters:
item (iTree) – iTree object to be searched for
start (Union[iTree,target_path]) – iTree item or start target_path where index search should be started (start item is included in search)
stop (Union[iTree,target_path]) – iTree item or stop target_path where index search should be stopped (stop item is not included in search)
;rtype: int :return: absolute index of the found item
- itertree.iTree.deep.index()
coded in helper-class:
- itertree.itree_indepth._iTreeIndepthTree.index()
Call via iTree().deep.index()
The index method allows to search for the index_path of a matching item in the iTree. The item must be a iTree object and the index will deliver the first match. The comparison is made via == operator.
Warning
If the user gives the start or stop argument not as an iTree-item but as a target_path he must give a list (or iterable) for targeting each level in the tree! The arguments are interpreted as the arguments for iTree.get().
This means if the user targets an element in first level by an absolute index he must give it as index(item,[index]) giving just the integer value will not work in this case!
If item is not found a IndexError will be raised
Note
To get the index of a specific item instance in his parent tree the .idx_path- property should be used.
- Parameters:
item (iTree) – iTree object to be searched for
start (Union[iTree,target_path]) – iTree item or start target_path where index search should be started (start item is included in search)
stop (Union[iTree,target_path]) – iTree item or stop target_path where index search should be stopped (stop item is not included in search)
;rtype: list :return: index_path of the found item
- itertree.iTree.count()
Counts how many equal (==) children are in the iTree-object.
- Parameters:
item (iTree) – The iTree-items will be compared with this item
- Return type:
int
- Returns:
Number of matching items found
- itertree.iTree.deep.count()
coded in helper-class:
- itertree.itree_indepth._iTreeIndepthTree.count()
Call via **iTree().deep.count()**`
Counts (in-depth) how many equal (==) items are inside the iTree-object.
- Parameters:
item (iTree) – The iTree-items will be compared with this item
- Return type:
int
- Returns:
Number of matching items found
- itertree.iTree.is_tag_in()
Checks if a iTree contains the given family-tag (first-level only) :param tag: family tag :return: True/False
- itertree.iTree.deep.is_tag_in()
coded in helper-class:
- itertree.itree_indepth._iTreeIndepthTree.is_tag_in()
Call via iTree().deep.is_tag_in()
Checks if a iTree contains the given family-tag (in_depth (all levels)) :param tag: family tag :return: True/False
iTree`s can also be compared with each other the criteria here is the size `__len__() of the objects. Based on this comparison operators < ; <= ; > ; >= are available. The methods exists in the level 1 children related variant (base-class) or in in-depth variant (use deep-sub-class).
For length calculations the following methods exists:
- itertree.iTree.__len__()
- itertree.iTree.deep.__len__()
coded in helper-class:
- itertree.itree_indepth._iTreeIndepthTree.__len__()
Call via len(iTree().deep)
Delivers number of all items (in-depth) inside the iTree-object
- Return type:
int
- Returns:
number of children and sub-children in iTree-object
- itertree.iTree.filtered_len()
Calculates the number of filtered children.
- Parameters:
filter_method (Callable) – filter method that checks for matching items and delivers True/False. The filter_method targets always the iTree-child-object and checks a characteristic of this object for matches (see filter_method)
- Return type:
int
- Returns:
Number of matching items found
- itertree.iTree.deep.filtered_len()
coded in helper-class:
- itertree.itree_indepth._iTreeIndepthTree.filtered_len()
Call via **iTree().deep.filtered_len()**`
Calculates in-depth the number of filtered items.
- Parameters:
filter_method (Union[Callable,None]) – filter method that checks for matching items and delivers True/False. The filter_method targets always the iTree-child-object and checks a characteristic of this object for matches (see filter_method)
hierarchical (bool) –
- True - hierarchical filtering if a parent does not match to the filter
the children are taken out too, and they are not considered
- False - non-hierarchical filtering (all items are checked against the
filter and considered in the result)
- Return type:
int
- Returns:
Number of matching items found
iTree properties
As we will see later on some properties of the iTree object can be modified by the related methods.
The iTree object contains the following general properties:
- property iTree.root
property delivers the root-item of the tree
In case the item has no parent it will deliver itself
- Return type:
- Returns:
iTree root item
- property iTree.is_root
Is this item a root-item (has no parent)?
- Return type:
bool
- Returns:
True - is root
False - is not root
- property iTree.parent
Property delivers current items parent-object.
- Return type:
Union[iTree, None]
- Returns:
iTree parent-object or None (in case no parent exists)
- itertree.iTree.ancestors()
Property delivers current items parents list up to the oot. In case item has no parent an empty list will be delivered
- Return type:
list
- Returns:
list of all ancestors
- property iTree.pre_item
Delivers the pre-item (predecessor) of this object in the parent-tree. If self is first item or there is no parent None will be delivered.
- Return type:
Union[iTree,None]
- Returns:
iTree predecessor or None (no match)
- property iTree.post_item
Delivers the post-item (successor) of this object in the parent-tree. If self is first item or there is no parent None will be delivered.
- Return type:
Union[iTree,None]
- Returns:
iTree successor or None (no match)
- property iTree.level
Delivers the distance (number of levels) to the root-item of the tree. Or in other words how deep in tree the item is positioned. In case item has no parent (is a root-item) this method will deliver 0.
- Return type:
int
- Returns:
integer - number of levels (outer direction)
- property iTree.max_depth
Relative from this item the method measures the maximum depth of the tree and delivers the maximum number of levels that are found in this object.
If the user wants to now the maximum depth of the whole tree ensure that the property of the root-item is read. The user might use my_tree.root.max_depth to ensure this.
- Return type:
int
- Returns:
integer maximal number of levels that exists in the tree (inner direction)
- property iTree.is_tree_read_only
Is the tree protection flag set? In this case the tree structure cannot be changed
This property targets the tree structure not the value!
- Return type:
bool
- Returns:
False - subtree can be changed (writeable)
True - subtree is protected (read-only)
- property iTree.is_value_read_only
Is iTree value read_only? Is the value protection flag iTFLAG.READ_ONLY_VALUE is set?
- Return type:
bool
- Returns:
True - read-only protection of value active False - value is writeable
- property iTree.is_linked
In contrast to iTreeLinked class this is False
- Return type:
bool
- Returns:
True/False
- property iTree.is_link_root
property that marks the iTree item as an item that contains a link
- Returns:
True - is a link root item
False is no iTree link item
- property iTree.is_link_cover
If the item is local and covers a linked item the property is True
- Return type:
bool
- Returns:
True/False
- property iTree.is_placeholder
Property shows that item is a placeholder class
Normally there should be no placeholder class in the iTree but in case a loaded link does no more contain the expected items it might happen that such a class artifact is still in the tree. In placeholders the value contains the family index in the linked class.
- Return type:
bool
- Returns:
True/False
Item identification properties:
- property iTree.idx
Index of this object in the iTree (related to the absolute order)
Method is very important for internal functionalities
Note
In general the item index is cached but in case of deleted items or reorder operations the cache might be outdated. In this case the index update based on a search might take longer.
- Return type:
Union[int, None]
- Returns:
unsigned integer representing the index (related to absolute order of iTree)
- property iTree.tag_idx
The tag_idx is a unique identification of the item. It is represented by a tuple containing the family-tag and the family related index of the item.
If the item is not part of a parent-tree (root-item) in this case the result will be None.
- Return type:
Union[tuple, None]
- Returns:
tuple (family-tag, family-index) or None (if item has no parent)
- property iTree.idx_path
delivers a list of absolute indexes from the root to this item
For items with no parent (root_item) an empty tuple will be delivered
Note
We deliver here a tuple because it might be helpful if the object is hashable (usage as a dict key)
- Return type:
tuple
- Returns:
tuple of index integers (here we do not deliver an iterator!)
- property iTree.tag_idx_path
The path is a tuple of tag_idx tuples from root to this item. Each tag_idx is a tuple containing the pair family-tag and family-index.
For items with no parent (rooot_item) an empty tuple will be delivered
Note
We deliver here a tuple because it might be helpful if the object is hashable (usage as a dict key)
- Return type:
tuple
- Returns:
tuple of key tuples containing family-tag and family-index
The following examples shows how some of the iTree-properties are read out.
>>> root = iTree('root', subtree=[iTree('child', 0), iTree((1, 2), 'tuple_child0'), iTree('child', 1), iTree('child', 2),iTree((1, 2), 'tuple_child1')])
>>> root[0] += iTree('subchild')
>>> root.render()
iTree('root')
> iTree('child', value=0)
. > iTree('subchild')
> iTree((1, 2), value='tuple_child0')
> iTree('child', value=1)
> iTree('child', value=2)
> iTree((1, 2), value='tuple_child1')
>>> root[0][0].root
iTree('root', subtree=[iTree('child', value=0, subtree=[iTree('subchild')]),...,iTree((1, 2), value='tuple_child1')])
>>> root[0][0].idx
0
>>> root[0][0].tag_idx
('subchild', 0)
>>> root[0][0].idx_path
(0, 0)
>>> root[0][0].tag_idx_path
(('child', 0), ('subchild', 0))
>>> root[1].value
tuple_child0
>>> root[1].tag_idx
((1, 2), 0)
>>> root[-1].value
tuple_child1
>>> root[-1].tag_idx
((1, 2), 1)
>>> len(root) # level 1 only
5
>>> len(root.deep) # all in-depth items
6
>>> root2=root.copy()
>>> root2[-1].append(iTree('subitem')) # we append one item in depth
iTree('subitem')
>>> root2>root # level 1 only size-compare
False
>>> root2.deep>root.deep # all items size-compare
True
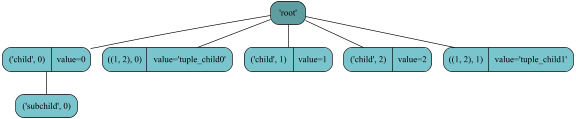
Figure showing iTree used in example
As shown in the last example hashable objects can be used as tags for the itertree items to be stored in the iTree object. Even for those kind of tag objects it is possible to store multiple items with the same tag. In the example the enumeration inside the tag family can be seen in the index enumeration (tag_idx).
Beside those structural properties the iTree objects contains a property that can be used to “link” the ìTree`-object to another Python object.
- property iTree.coupled_object
The iTree-object can be coupled with another Python-object. The pointer to the object is stored and can be reached via this property. (E.g. this can be helpful when connecting the iTree with a visual item (hypertree-list item) in a GUI)
- Returns:
pointer to coupled-object or None if no object is stored
- itertree.iTree.set_coupled_object()
Couple another Python-object with this iTree-object.
Compared with the value the coupled-object is not tracked by any internal functions. We do not consider it in any relation (e.g. __contains__() and do not dump it in files, etc. Even in linked items the coupled-object is not protected. And in copies it is ignored and not taken over.
Note
E.g. The coupled-object might be an object in a GUI that is related to this item.
- Parameters:
coupled_object – object pointer to the object that should be coupled with this iTree item
Different than the data the coupled_obj the idea is here to have just a pointer to another Python object. The only operations considering those objects is in the link root were during reload or if a linked item is converted in a local item the couple object will be taken over. The equal() compare function can also target the coupled-object.
Note
Behind this objects is the following idea: E.g. The user might couple the iTree to a graphical user interface object. Connect it with an item in a hypertree-list. Or it can be used to couple the iTree object to an item in a mapping dictionary. The property coupled-object is not actively managed by the iTree object it’s just a place to store a pointer. E.g. If iTree is stored in a file or standard compares this information will not be considered.
There can be cases where it is helpful to use this additional possibility to store information in the iTree too. E.g. in the attached calendar.example.py we use the coupled-object to store the day-name.
iTree iterations
As the name itertree suggests we have a lot of possibilities to iterate over the items in the tree-structure. In the class the we use generators (yield-statement) to create the output for the iterations.
Note
The class doesn’t contain a __next__()-method. This means if the given iteration methods are used (generators inside) the user must cast those generators for functions targeting the __next__() via the build-in iter()-statement. But most often this is not required because by most functionalities the supported __iter__() method is targeted.
In iTree we have iteration-generators which are more related to list-like functionalities and other which are targeting more in the direction of the dict-like iterators.
Most iteration-generators are available in different level behavior:
The children only variant iterating only over the items in level 1 of the tree-structure
In the in-depth variant which iterates as a flatten iterator over all the nested children.
First we show the list like standard iterator which delivers the children in the main/absolute order of the iTree-object.
- itertree.iTree.__iter__()
- itertree.iTree.siblings()
- Property delivers all siblings of the item. Iterates over all children of the parent and skips the item itself
In case of no siblings an empty list is delivered.
In case of an unique sibling a list with the unique sibling is delivered
In case of multiple siblings a generator (iterator) over all siblings is delivered
:rtype Union(list,generator) :return: iterable over the siblings
Note
The siblings iterator does not consider the item itself. If you need an iterator that considers the item itself use: mytree.parent.__iter__().
Some more dict-like iteration-methods targeting the children (level 1 only) are:
- itertree.iTree.keys()
Iterates over all children and deliver the children tag-idx tuple (family-tag,family_index)
Note
This is a dict like iterator that delivers the unique keys for all children.
- Parameters:
filter_method (Union[Callable,None]) –
filter method that checks the item and delivers True/False. The filter_method targets always the iTree-child-object and checks a characteristic of this object for matches
If None is given filtering is inactive.
- Return type:
Iterator
- Returns:
iterator over the tag-idx of the children
- itertree.iTree.values()
Iterates over all children and deliver the children values
- Parameters:
filter_method (Union[Callable,None]) –
filter method that checks for matching items and delivers True/False. The filter_method targets always the iTree-child-object and checks a characteristic of this object for matches (see filter_method)
If None is given filtering is inactive.
- Return type:
Iterator
- Returns:
iterator over the values stored in the children
- itertree.iTree.items()
Iterates over all children and deliver the children item-tuples (key,item) or (key,value). As key we use the unique tag-idx: (tag-family,family-index).
The function is comparable with dicts items() function.
- Parameters:
filter_method (Union[Callable,None]) –
filter method that checks for matching items and delivers True/False. The filter_method targets always the iTree-child-object and checks a characteristic of this object for matches (see filter_method)
If None is given filtering is inactive.
values_only (bool) –
False (default) - in the key,value tuple the iterator put the iTree object as value in
True - in the key,value tuple the iterator put “only” the value object of the iTree-object in
- Return type:
Generator
- Returns:
iterator over the target keys and item value of the children
To make the delivered generator-content visible we use the list()-cast in the following examples:
>>> # create a small nested iTree:
>>> root = iTree('root', subtree=[iTree('one', 1, subtree=[iTree('subone', 1.1), iTree('subtwo', 1.2)]), iTree('two', 2), iTree('three', 3)])
>>> list(root) # __iter__()
[iTree('one', value=1, subtree=[iTree('subone', value=1.1), iTree('subtwo', value=1.2)]), iTree('two', value=2), iTree('three', value=3)]
>>> list(root)
[iTree('one', value=1, subtree=[iTree('subone', value=1.1), iTree('subtwo', value=1.2)]), iTree('two', value=2), iTree('three', value=3)]
>>> list(root.values())
[1, 2, 3]
>>> list(root.tag_idxs())
Traceback (most recent call last):
...
AttributeError: 'iTree' object has no attribute 'tag_idxs'
>>> list(root.items())
[(('one', 0), iTree('one', value=1, subtree=[iTree('subone', value=1.1), iTree('subtwo', value=1.2)])), (('two', 0), iTree('two', value=2)), (('three', 0), iTree('three', value=3))]
>>> list(root.items(values_only=True))
[(('one', 0), 1), (('two', 0), 2), (('three', 0), 3)]
We have some special iteration-methods related to the item access based on the groups created by tag-families. The delivered items are ordered by the first item (or the last - if parameter is set) in the family and the iteration runs over all items of the first familly then all items of the next and so on.
- itertree.iTree.tags()
iters over all family-tags in level 1 (children). The order is based on first or last item in the family.
- Parameters:
order_last (bool) –
False (default) - The tag-order is based on the order of the first items in the family
True - The tag-order is based on the order of the last items in the family
- Return type:
Iterator
- Returns:
tag iterator
- itertree.iTree.iter_families()
This is a special iterator that iterates over the families in iTree. It delivers per family the tag and a list of the containing items. The order is defined by the absolute index of the first item in each family
Method will be reached via iTree.Families.iter()
- Parameters:
filter_method (Union[Callable,None]) –
filter method that checks for matching items and delivers True/False. The filter_method targets always the iTree-child-object and checks a characteristic of this object for matches (see filter_method)
If filter_method is None no filtering is performed
Note
An internal filtering is available because this may change the order of the delivered items. An external filter with same method might deliver a different result!
order_last (bool) –
False (default) - The tag-order is based on the order of the first items in the family
True - The tag-order is based on the order of the last items in the family
- Return type:
Generator
- Returns:
iterator over all families delivers tuples of (family-tag, family-item-list)
- itertree.iTree.iter_family_items()
This is a special iterator that iterates over the families in iTree. It iters over the items of each family the ordered by the first or the last items of the families.
- Parameters:
order_last (bool) –
False (default) - The tag-order is based on the order of the first items in the family
True - The tag-order is based on the order of the last items in the family
- Return type:
Generator
- Returns:
iterator over all families delivers tuples of (family-tag, family-item-list)
Note
The family structure inside iTree cannot be made available directly because this would give the user the possibility of corrupting manipulations. But the user can use those family related iteration functions if he wants to create a representation of the family structure.
Most in-depth iteration-methods have additional parameters:
filter_method filter parameter which allows the hierarchical-filtering inside the iteration loops.
options allows to select the direction of the iteration via flags:
ITER.DOWN - top to down level iteration (default)
ITER.UP - down to top level iteration
ITER.REVERSE - The children of a item are iterated in the reversed direction (high index to zero index). The default iteration direction for the children is zero index to highest index)
ITER.SELF - In the iteration the calling object (self) will be included. The default is that the calling object is not part of the iteration
ITER.FILTER_ANY - This flag has effect if a filter_method is given. It enables the pythons build_in filter() on any iterated object. The default is a hierarchical filtering.
All the in-depth iteration-methods are reached via the helper class iTree.deep:
- itertree.iTree.deep.__iter__()
coded in helper-class:
- itertree.itree_indepth._iTreeIndepthTree.__iter__()
Call via: iter(iTree().deep)
In-depth generator (iterator) which iterates over all nested items of iTree top -> down direction
- Return type:
Generator
- Returns:
iterator over all ìTree`-items
- itertree.iTree.deep.iter()
coded in helper-class:
- itertree.itree_indepth._iTreeIndepthTree.iter()
In-depth iterator that iterates over all items in the nested iTree-structure. The iterator flattens the nested structure. In an instanced iTree-object the method is reached via: iTree().deep.iter().
The way we iterate depends on the given iteration options (combine options with | (OR bit operator)):
ITER.UP - Iteration will be made bottom->up (from the deepest items to the root), The default iteration direction is top -> down
ITER.REVERSE - The children of a item are iterated in the reversed direction (high index -> zero index). The default iteration direction for the children is zero index ->o highest index)
ITER.SELF - In the iteration the calling object (self) will be included. The default is that the calling object is not part of the iteration
ITER.FILTER_ANY - This flag has effect if a filter_method is given. It enables the pythons build_in filter() on any iterated object. The default is a hierarchical filtering.
Other iteration flags are not supported by this function
Note
The call for item in mytree.deep.iter(): is same as for i in mytree.deep. Calling `iter() ` without parameters is same as `__iter__()’.
- Parameters:
filter_method (Union[Callable,None]) –
filter method that checks for matching items and delivers True/False. The filter_method targets always the iTree-child-object and checks a characteristic of this object.
If None (default) is given no filtering will be performed.
option (int) – Supported iteration options: ITER.UP | ITER.REVERSE | ITER.SELF | ITER.FILTER_ANY
- Return type:
Generator
- Returns:
iterator over all nested ìTree`-items
We have several options which influences the way we iterate over the tree they can be combined (e.g. ITER.REVERSE | ITER.SELF):
ITER.UP - changes the default up-down direction of the iteration into bottom up.
ITER.REVERSE - switches the iteration direction from standard low index to high index to high index to low index.
ITER.SELF - include the item itself into the iteration (In up-down direction the item itself will be first in the other direction it will be the elast element iterated)
ITER.FILTER_ANY - This flag has effect if a filter_method is given. It enables the pythons build_in filter() on any iterated object (non hierarchical filtering). The default is a hierarchical filtering.
>>> root = iTree('root')
>>> for i in range(2):
item=root.append(iTree('%i'%i, i))
for ii in range(2):
subitem = item.append(iTree('%i_%i' % (i,ii), i*10+ii))
for iii in range(2):
subitem.append(iTree('%i_%i_%i' % (i, ii,iii), i * 100 + ii*10+iii))
>>> [i for i in root.deep.iter(options=ITER.DOWN)][0:5] # show just a part
[iTree('0', value=0, subtree=[iTree('0_0', value=0, subtree=[iTree('0_0_0', value=0), iTree('0_0_1', value=1)]), iTree('0_1', value=1, subtree=[iTree('0_1_0', value=10), iTree('0_1_1', value=11)])]), iTree('0_0', value=0, subtree=[iTree('0_0_0', value=0), iTree('0_0_1', value=1)]), iTree('0_0_0', value=0), iTree('0_0_1', value=1), iTree('0_1', value=1, subtree=[iTree('0_1_0', value=10), iTree('0_1_1', value=11)])]
>>> [i for i in root.deep.iter(options=ITER.UP)][0:5] # show just a part
[iTree('0_0_0', value=0), iTree('0_0_1', value=1), iTree('0_0', value=0, subtree=[iTree('0_0_0', value=0), iTree('0_0_1', value=1)]), iTree('0_1_0', value=10), iTree('0_1_1', value=11)]
The figures should show the scheme of iteration for the different parameter settings.

Figure shows the meanings of the different symbols used in the following figures.
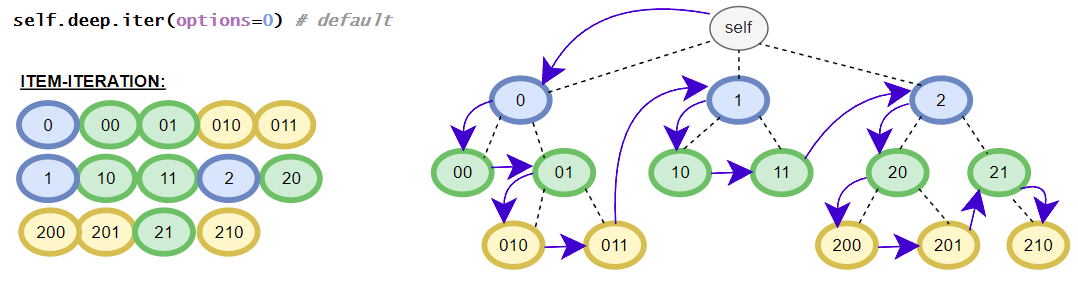
Figure schema for standard up->down (default) iteration
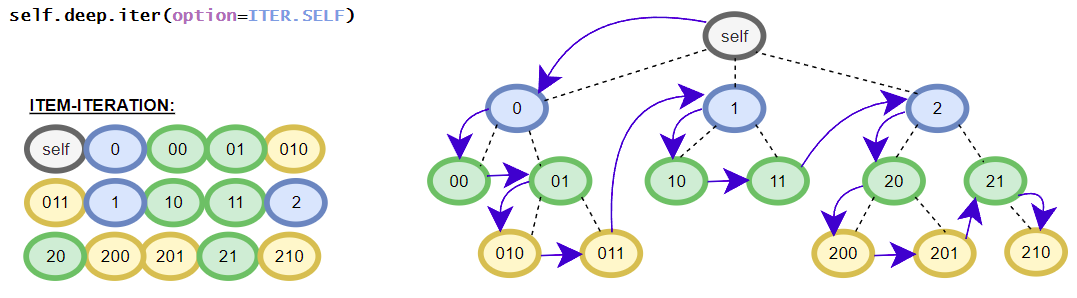
Figure schema for standard up->down (default) iteration including self
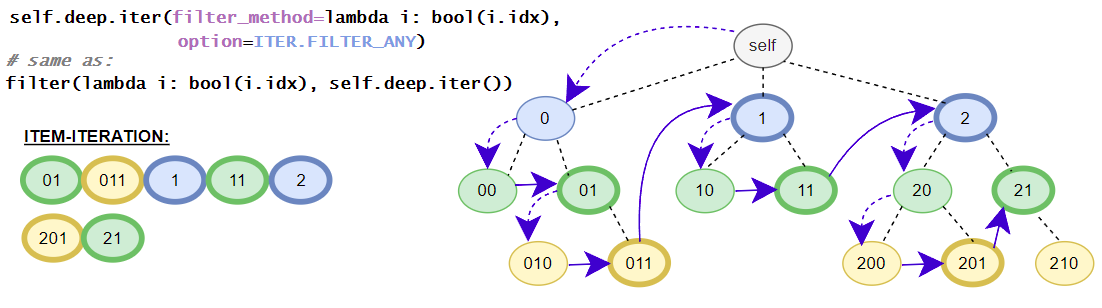
Figure schema for standard up->down (default) iteration showing the effect of external filtering (all elements with item.idx==0 or item.idx==None are filtered out)
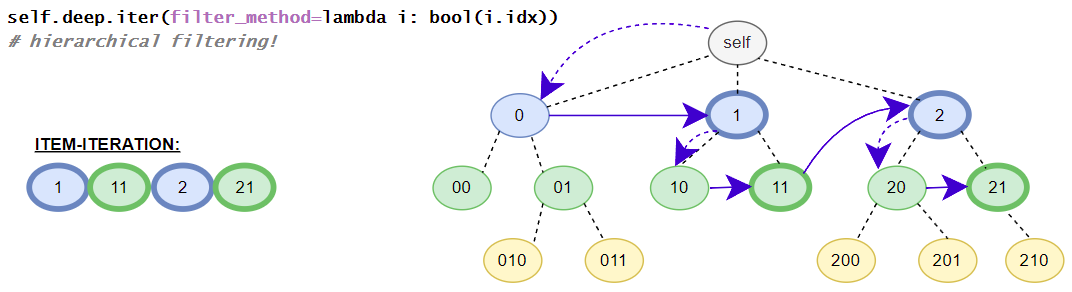
Figure schema for standard up->down (default) iteration showing the effect of internal hierarchical filtering (all elements with item.idx==0 or item.idx==None are filtered out)
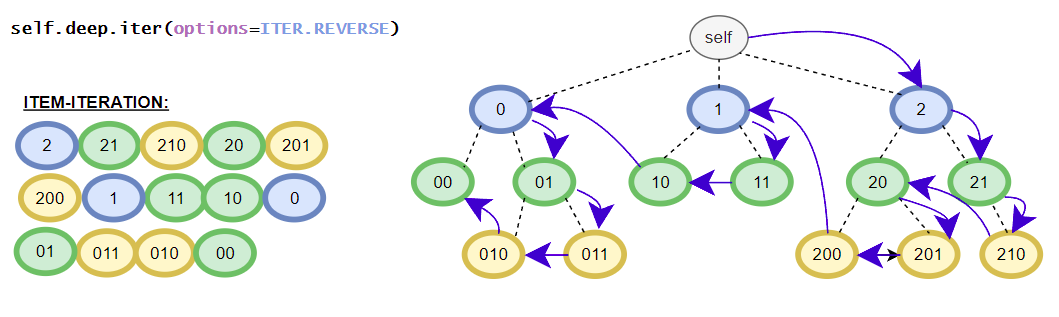
Figure schema for standard up->down (default) iteration but with reversed indexing of the items
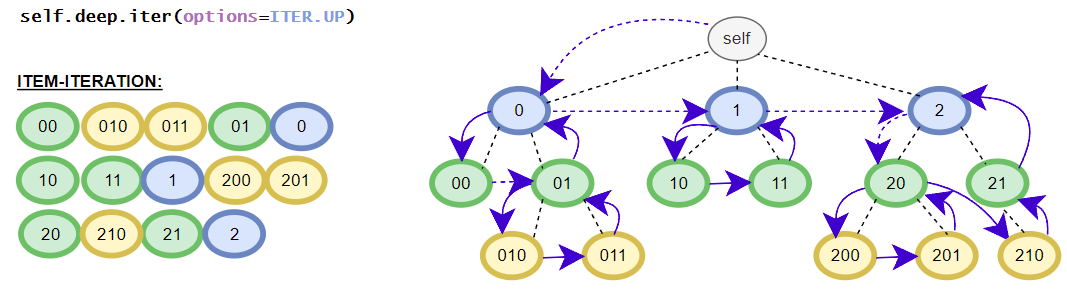
Figure schema for down->up iteration
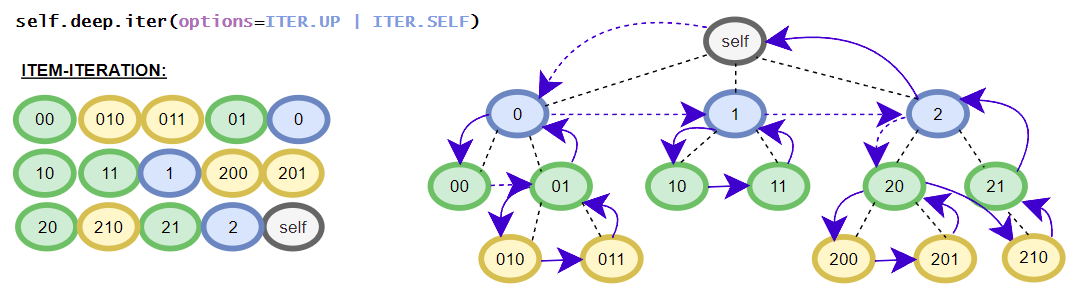
Figure schema for down->up iteration including self
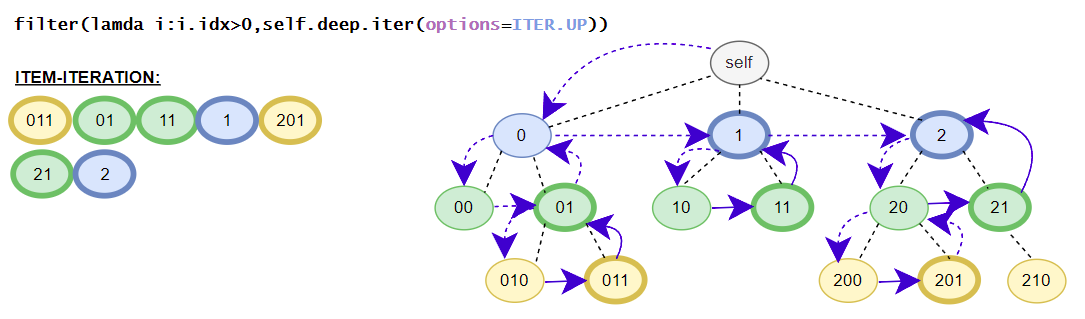
Figure schema for down->up iteration showing the effect of external filtering (all elements with item.idx==0 are filtered out)
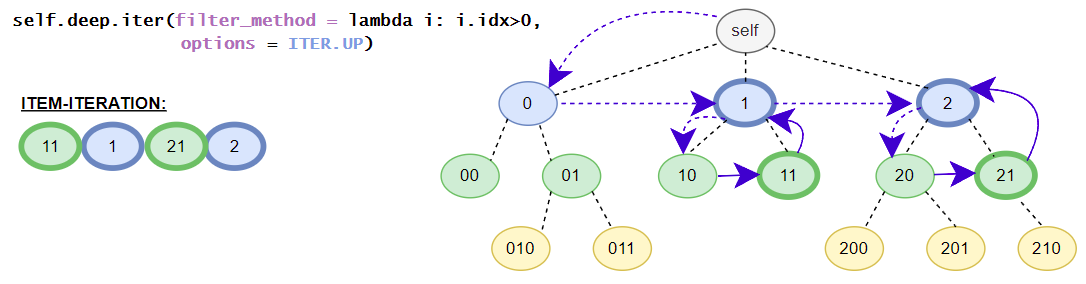
Figure schema for down->up iteration showing the effect of internal hierarchical filtering (all elements with item.idx==0 are filtered out)
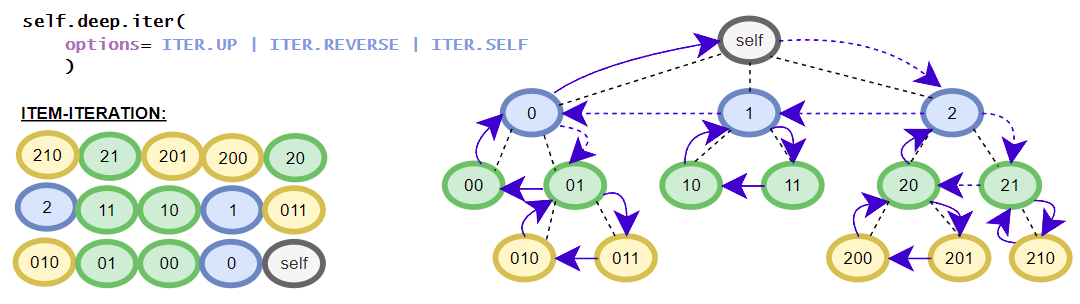
Figure schema for down->up iteration but with reversed indexing of the items including self
- itertree.iTree.deep.siblings()
coded in helper-class:
- itertree.itree_indepth._iTreeIndepthTree.siblings()
Call via iTree().deep.siblings()
This generator iterates over all siblings in the targeted level in the calling item.
The way we iterate depends on the given iteration options (combine options with | (OR bit operator)):
ITER.REVERSE - The item in the level will be iterated in the reversed direction (high index -> low index). The default iteration direction is low index ->o highest index)
ITER.SELF - In the iteration the calling object (self) will be included. The default is that the calling object is not part of the iteration
- ITER.MULTIPLE - allows multiple matches of one item during the iteration
(can happen in case of negative level values)
Other iteration flags are not supported by this method. For better understanding we recommend the related section in the tutorial where the behavior is explained in diagrams.
Note
The method supports negative target levels. In this case the iteration might not stay in same absolute level! (e.g. The call mytree.deep.siblings(-1) will deliver all ending items (no children) of mytree. In case the branches inside mytree have different depth the iteration will step in the related positive levels up and down. In case of the iteration finds same item again it will not be delivered again in the resulting generator (a sibling will be considered only one time during the iteration).
- Parameters:
level (int) – target level. The target level can be negative too.
option (int) – Supported iteration options: ITER.REVERSE | ITER.SELF | ITER.MULTIPLE
- Return type:
Generator
- Returns:
iterator over specif level of the tree
In the in_depth variant the siblings class steps down the levels from the current itree objects and deliver all items in same level relative level. The absolute level can be targeted if the method is called from the root object.
The function accepts negative levels too. Here the method is always calculating the level from the “bottom” of the tree. It can be that in those iterations the same item is targeted multiple times. By default the function will deliver the items only at the first time they are yielded. Additional matches are skipped. If the flag ´ITER:MULTIPLE´ is set the items delivered each time. Interesting cases might be:
mytree.root.deep.siblings(mytree.level) - Iter over all siblings in the full tree in the same level as the calling item (absolute level in the tree from the root).
mytree.deep.siblings(-1) - Iter over all “bottom” items in the subtree of the calling item.
mytree.root.deep.siblings(-1) - Iter over all “bottom” items in the full tree from root.
Have a deep look on the figures showing the wide range of possible iteration related to the given options.
Figure shows the meanings of the different symbols used in the following figures.
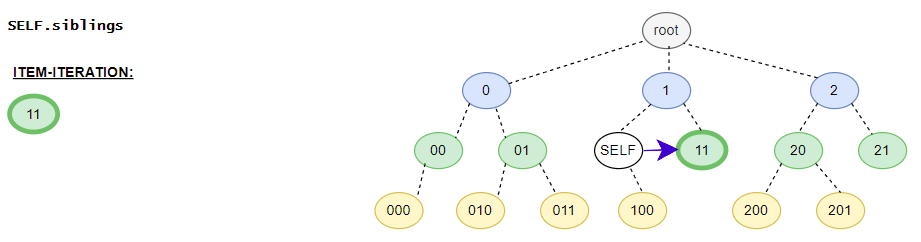
The figure shows the simple (not in_depth) sibling function.
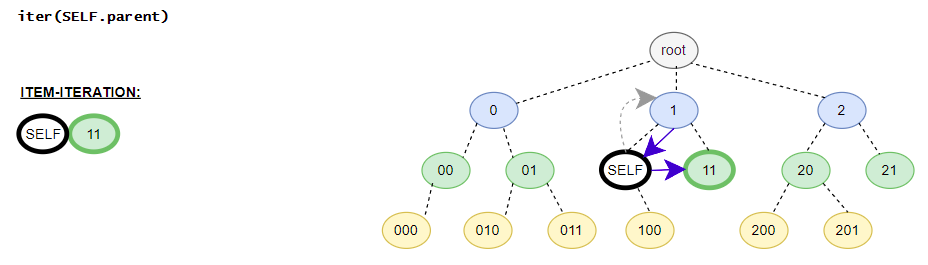
The figure shows how the item itself is included by iterating over the children of the parent object. (not in_depth) sibling function.
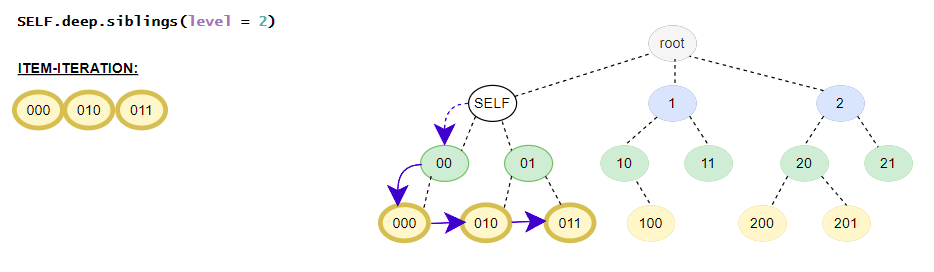
The figure shows the iteration over the level 2 siblings relative the calling object.
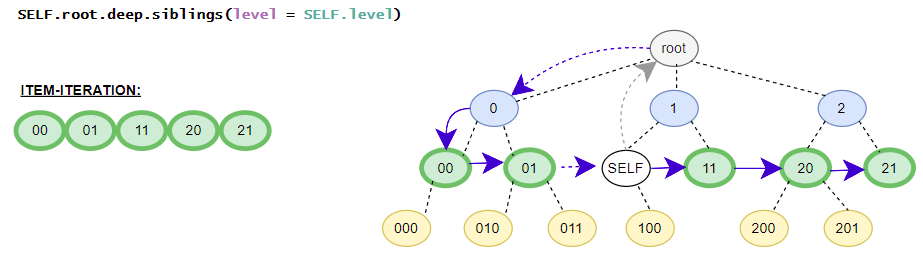
The figure shows the iteration over the same level siblings (SELF.level property used as level parameter) as absolute level from root. The root is targeted by mytree.root property from the calling object.
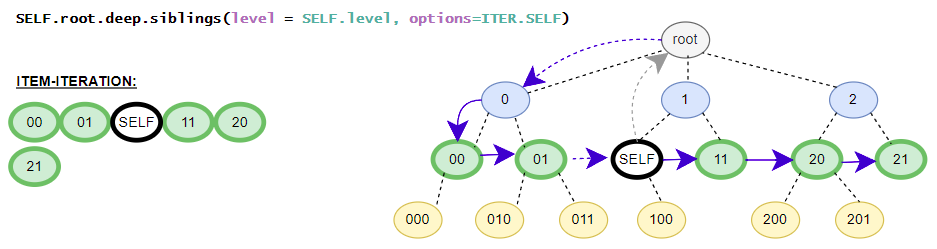
The figure shows the iteration over the same level siblings (SELF.level property used as level parameter) as absolute level from root. The root is targeted by mytree.root property from the calling object. Because the ITER.SELF option is given the item itself is included in the iteration.
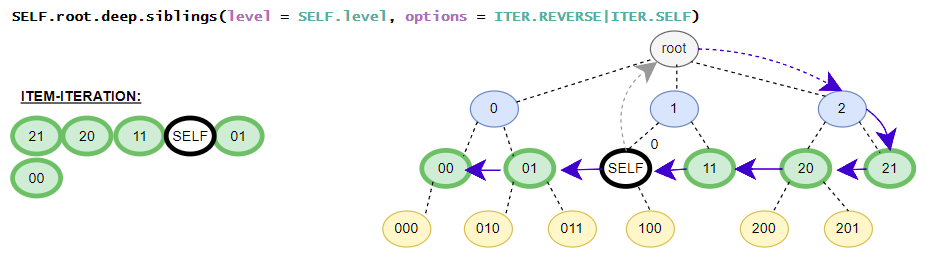
The figure shows the iteration in reversed order (high -> low index) over the same level siblings (SELF.level property used as level parameter) as absolute level from root. The root is targeted by mytree.root property from the calling object. Because the ITER.SELF option is given the item itself is included in the iteration.
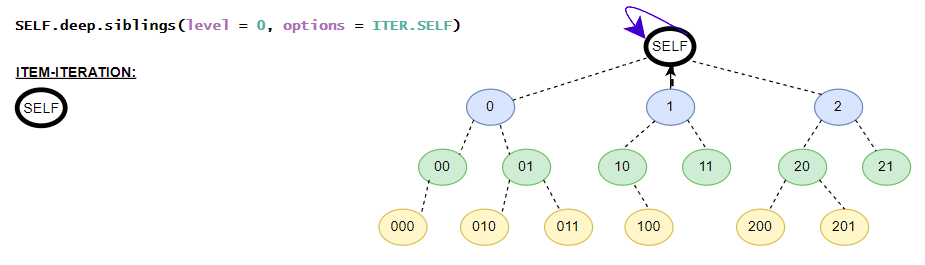
The figure shows a special cornercase. The relative level 0 iteration over the full tree on the level of the calling item itself. Because of ITER.SELF-option-flag the item itself is considered in the iteration. Without the flag an empty iterator would be given.
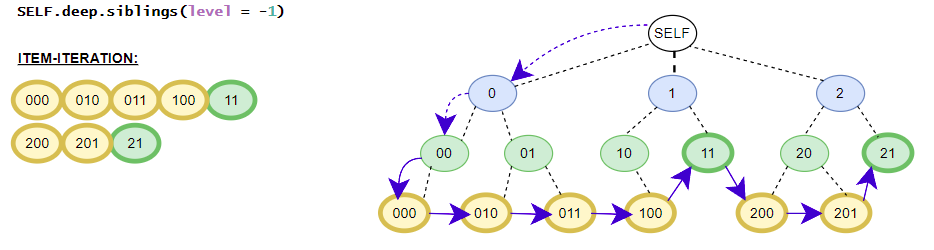
The figure shows the iteration of all “bottom” items in the sub-tree (from caller).
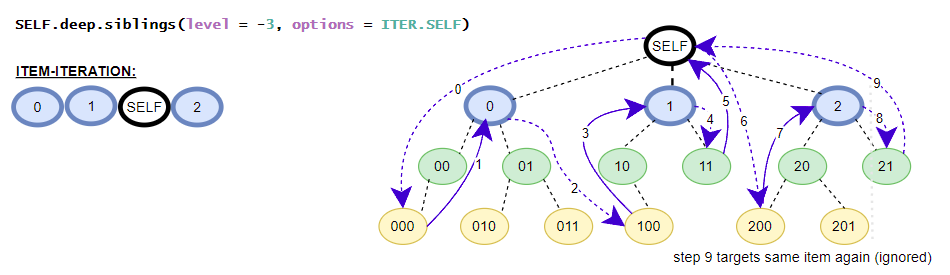
The figure shows the iteration over all items with a distance of three levels from the bottom. The calling item itself is include into the iteration because the ITER.SELF option is given. We see that for negative levels it can be that specific items are matching multiple times for the given condition. By default only the first match will be yielded into the iterator. Additional matches will be ignored. Each item will be target only one time.
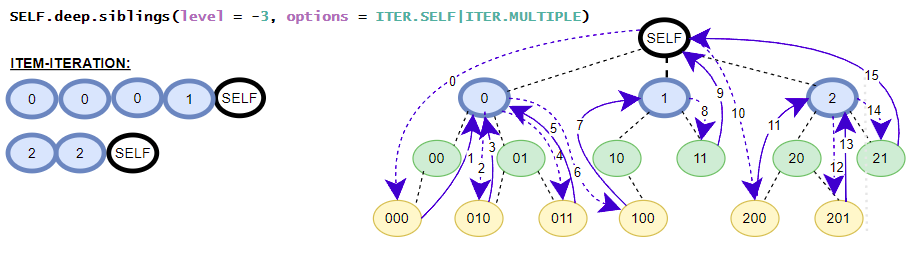
The figure shows the iteration over all items with a distance of three levels from the bottom. The calling item itself is include into the iteration because the ITER.SELF option is given. In this case the ITER.MULTI option is set which means the items will be yielded when ever they match. This means it can be that a specific item can be delivered multiple times.
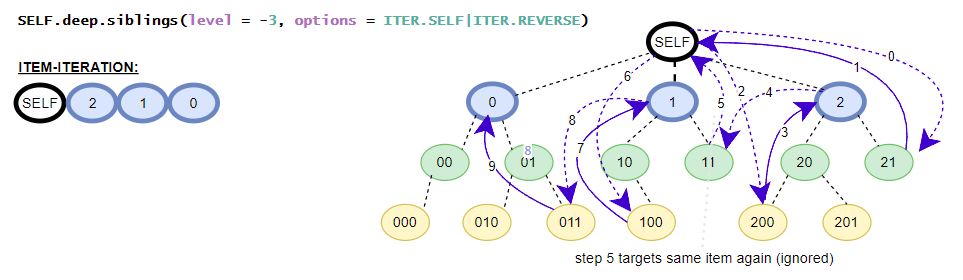
The figure shows the iteration over all items in reversed (high -> low index) order with a distance of three levels from the bottom. The calling item itself is include into the iteration because the ITER.SELF option is given.
- itertree.iTree.deep.levels()
coded in helper-class:
- itertree.itree_indepth._iTreeIndepthTree.levels()
Multilevel iteration generator. This method iterates over the items level by level based on the given levels.
As options the user can give:
ITER.SELF - the calling object itself will be included, by default it is excluded
ITER.REVERSE - Go from high to low index per level
- ITER.MULTIPLE - Allows that one item can be iterated multiple times
(especially in case of negative levels this is possible)
Note
In general the method behaves like the siblings method executed on multiple levels.
def levels(levels, options): for level in levels: for item in siblings(level,options) yield item
Different to the shown replacement function the level function is optimized and should be quicker compared to the shown code. Especially if the user give slices of levels (which is possible too).
Note
In case a list or iterable of levels is given and level values are repeated (e.g. levels = [1,1,1]) This generator function will iterate multiple times over the level items. But without the flag, ITER.MULTIPLE an already yielded item will not be repeated!
- Parameters:
levels (Union(Iterable,Slice)) – Iterable of level values (each item must be an integer). If slices are given they are translated in a loop with related range() parameters.
options (int) – ITER option flags, possible values are ITER.SELF|ITER.REVERSE|ITER.MULTIPLE
- Returns:
Iteration generator
The levels() iteration generator is feeded with multiple levels (slice or iterable of integers) and it will iterate of the given levels as the siblings() method does it for one level only.
E.g.:
mytree.deep.levels(levels=[1,2]) == itertools.chain([mytree.deep.siblings(1),mytree.deep.siblings(2)]) mytree.deep.levels(levels=[1]) = mytree.deep.siblings(1)
It’s possible to run through the same level multiple times. But each item will be yielded onl yone time, except ´ITER.MULTIPLE` option is set.
In huge trees and with negative levels the iteration can take longer time. For negative levels the items must be calculated from low level items, this extra effort leads in slower iteration times.
Some interesting iterations created by deep.levels() method might be:
mytree.root.deep.levels(options=ITER.SELF) - iterates over all levels of the tree from the root the calling item itself is part of the iteration.
mytree.root.deep.levels(slice(-1,None,-1),options=ITER.SELF|ITER.ABS) - iterates over all levels of the tree from the root in bottom up direction. The calling item itself is part of the iteration.
Iteration examples related to the deep.levels()-method. Please remember that the method beahves like a cascaded deep.siblings() method. If the result is to confusing you might first have a look how the deep.siblings()-method works.
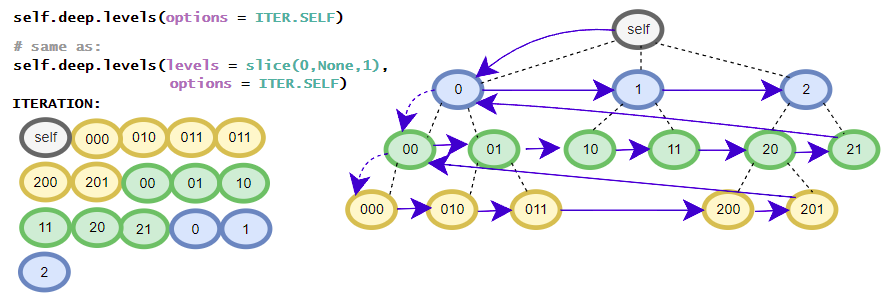
The figure shows the default iteration of the deep.levels() method. Because option ´ITER.SELF´ is set the item itself is yielded as first item in the iteration.
The default levels parameter value is a slice(0,None,1). It starts with relative level 0 (related to caller item) and steps over all levels in down direction.
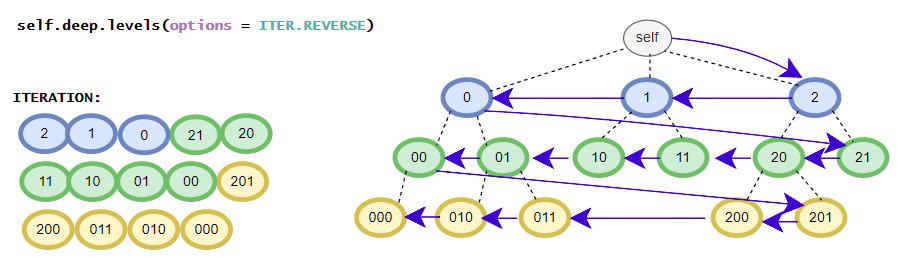
The figure shows the default iteration of the deep.levels() method but in reversed order (high–> low index). Here SELF is not included because ITER.SELF is not set.
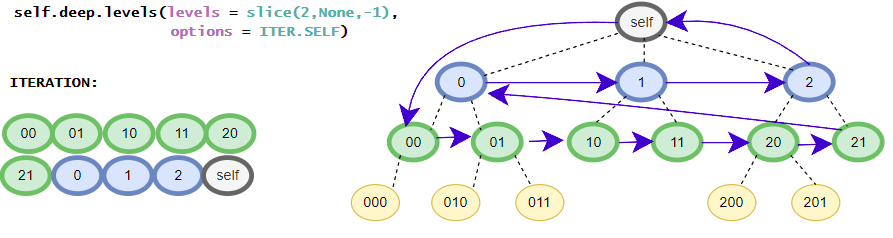
The figure shows an iteration over all levels in bottom->up order via slicing (2,None,-1). The calling item is included via option ITER.SELF.
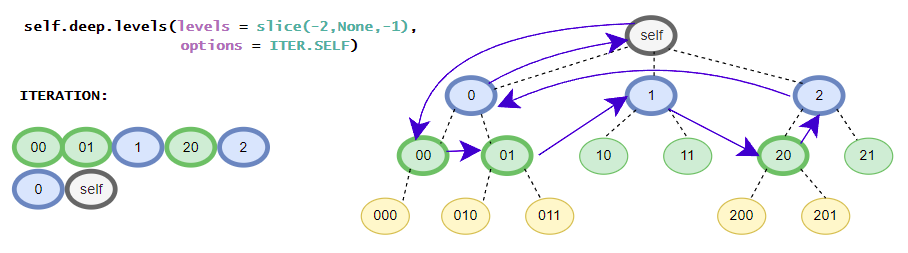
The figure shows an iteration over all levels in bottom->up order via slicing (-2,None,-1). The calling item is included via option ITER.SELF.
Different as in the example before we see if giving a negative index as start level in the slice (here -2) the iterator will calculate the levels from the bottom upward.
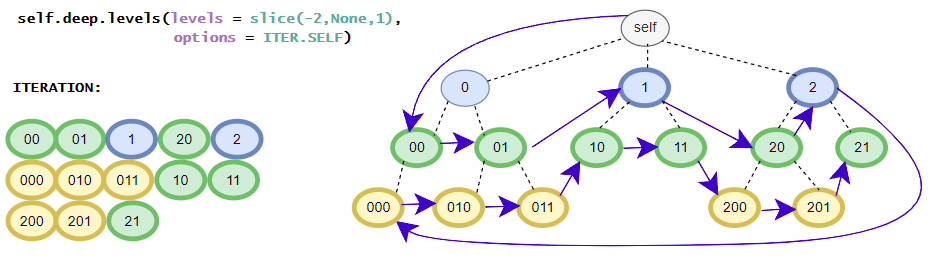
The figure shows an iteration over all levels down via slicing (-2,None,1). The calling item is included via option ITER.SELF.
Again we see a different behavior in the example the level is again calculated from the bottom but the slice increases the target level (-> -2, -1) so the iterator dives deeper into the tree. It stops after the deepest level is reached.
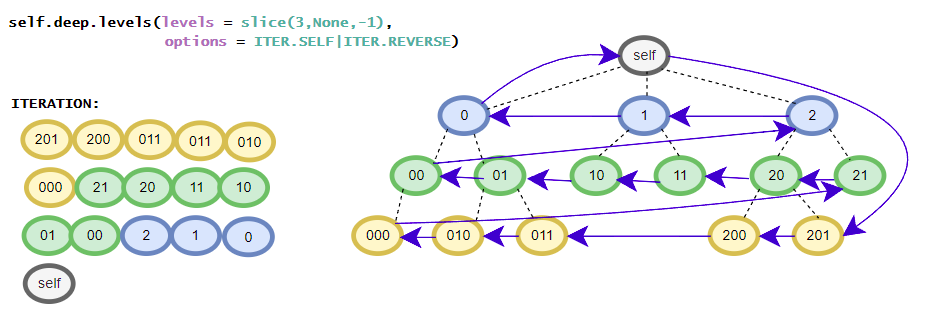
The figure shows an iteration over all levels in bottom up order via slicing (3,None,-1). The iteration direction is reversed (high-> low index) and SELF is included.
Now we look on some levels iterations using level lists instead of slices.
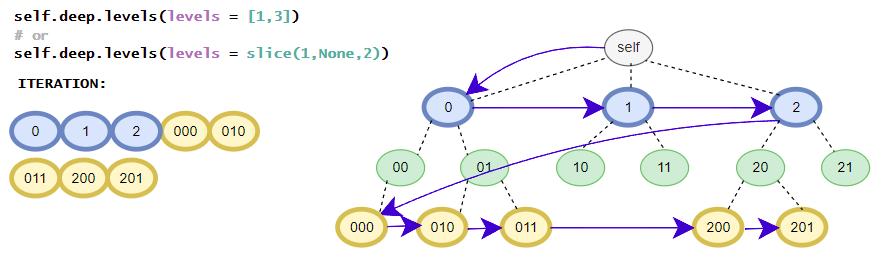
The figure shows an levels iteration over the levels 1 and 3.
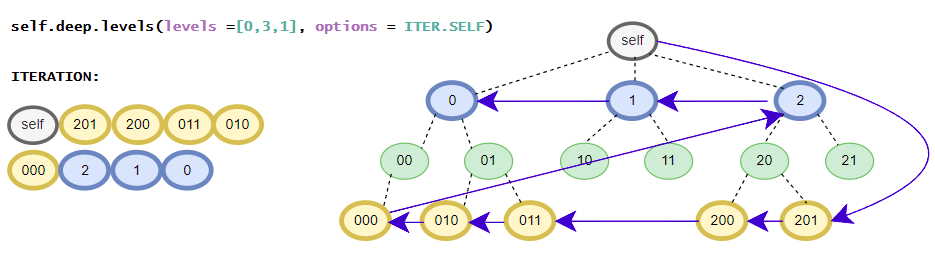
The figure shows an levels iteration over the levels 0; 1; 3 because `ITER.SELF`option is `SELF`is yielded too.
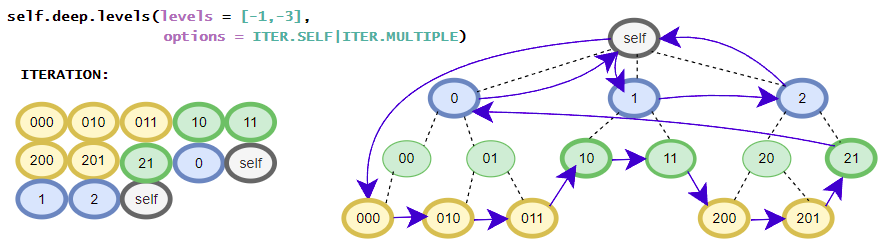
The figure shows an levels iteration over the levels -1 and -3. Options ITER.SELF and ITER.MULTIPLE are activated.
For negative levels or if the user uses one level multiple times in the given levels list itc can be that one item is found multiple times in the iteration. But only if the option ITER.MULTIPLE is set it will be delivered if not only first match is delivered and all items in the iteration are unique (see next example).
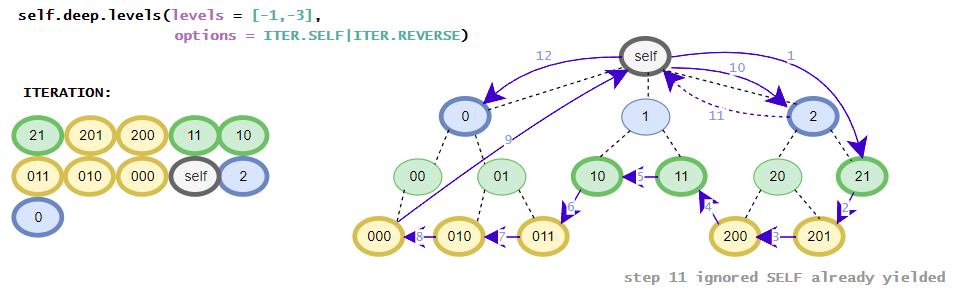
The figure shows an levels iteration over the levels -1; -3 in reversed order (high-> low index). Because ITER.MULTIPLE is not set iteration steps of already delivered items are skipped.
Additional we have the in-depth iteration-methods:
- itertree.iTree.deep.idx_paths()
coded in helper-class:
- itertree.itree_indepth._iTreeIndepthTree.idx_paths()
Call via: iTree().deep.idx_paths()
In-depth iterator that iterates over all items in the nested iTree-structure. The iterator flattens the nested structure. In general the method iters the same way as the “normal” deep.iter()-method but it yields the tuple (item.idx_path, item) per item.
The way we iterate depends on the given iteration options (combine options with | (OR bit operator)):
ITER.UP - Iteration will be made bottom->up (from the deepest items to the root), The default iteration direction is top -> down
ITER.REVERSE - The children of a item are iterated in the reversed direction (high index -> zero index). The default iteration direction for the children is zero index ->o highest index)
ITER.SELF - In the iteration the calling object (self) will be included. The default is that the calling object is not part of the iteration
ITER.FILTER_ANY - This flag has effect if a filter_method is given. It enables the pythons build_in filter() on any iterated object. The default is a hierarchical filtering.
Other iteration flags are not supported by this function.
- Parameters:
filter_method (Union[Callable,None]) –
filter method that checks for matching items and delivers True/False. The filter_method targets always the iTree-child-object and checks a characteristic of this object.
If None (default) is given no filtering will be performed.
option (int) – Supported iteration options: ITER.UP | ITER.REVERSE | ITER.SELF | ITER.FILTER_ANY
- Return type:
Generator
- Returns:
iterator over all nested ìTree`-items (delivers the tuple (item.idx_path, item) per item)
- itertree.iTree.deep.tag_idx_paths()
coded in helper-class:
- itertree.itree_indepth._iTreeIndepthTree.tag_idx_paths()
Call via: iTree().deep.tag_idx_paths()
In-depth iterator that iterates over all items in the nested iTree-structure. The iterator flattens the nested structure. In general the method iters the same way as the “normal” deep.iter()-method but it yields the tuple (item.tag_idx_path, item) per item.
The way we iterate depends on the given iteration options (combine options with | (OR bit operator)):
ITER.UP - Iteration will be made bottom->up (from the deepest items to the root), The default iteration direction is top -> down
ITER.REVERSE - The children of a item are iterated in the reversed direction (high index -> zero index). The default iteration direction for the children is zero index ->o highest index)
ITER.SELF - In the iteration the calling object (self) will be included. The default is that the calling object is not part of the iteration
ITER.FILTER_ANY - This flag has effect if a filter_method is given. It enables the pythons build_in filter() on any iterated object. The default is a hierarchical filtering.
Other iteration flags are not supported by this function.
- Parameters:
filter_method (Union[Callable,None]) –
filter method that checks for matching items and delivers True/False. The filter_method targets always the iTree-child-object and checks a characteristic of this object.
If None (default) is given no filtering will be performed.
option (int) – Supported iteration options: ITER.UP | ITER.REVERSE | ITER.SELF | ITER.FILTER_ANY
- Return type:
Generator
- Returns:
iterator over all nested ìTree`-items (delivers the tuple (item.tag_idx_path, item) per item)
- itertree.iTree.deep.iter_family_items()
coded in helper-class:
- itertree.itree_indepth._iTreeIndepthTree.iter_family_items()
Call via: iTree().deep.iter_family_items()
This is a special iterator that iterates over the families in iTree-class. It iters over the items of each family the ordered by the first or the last items of the families.
Note
As an exception this in-depth iteration-method does not support level-filtering because in an iteration based on tag-family items we do not see any sense in hierarchical filtering. Only external filtering of the resulting elements makes sense.
- Parameters:
order_last (bool) –
False (default) - The tag-order is based on the order of the first items in the family
True - The tag-order is based on the order of the last items in the family
- Return type:
Generator
- Returns:
iterator over all families delivers tuples of (family-tag, family-item-list)
Related to tag_family sorted iterations we have in-depth only the ìter_family_items() mathod available.
In the following example we create based on the in-depth generators lists and dicts:
>>> # deep iterators:
>>> list(root.deep) # deep counterpart of level1 __iter__() iterator
[iTree('one', value=1, subtree=[iTree('subone', value=1.1), iTree('subtwo', value=1.2)]), iTree('subone', value=1.1), iTree('subtwo', value=1.2), iTree('two', value=2), iTree('three', value=3)]
>>> list(root.deep.iter(options=ITER.UP)) # changed iteration order bottom-> up
[iTree('subone', value=1.1), iTree('subtwo', value=1.2), iTree('one', value=1, subtree=[iTree('subone', value=1.1), iTree('subtwo', value=1.2)]), iTree('two', value=2), iTree('three', value=3)]
>>> list(root.deep.tag_idx_paths()) # deep counterpart of level1 items() iterator
[((('one', 0),), iTree('one', value=1, subtree=[iTree('subone', value=1.1), iTree('subtwo', value=1.2)])), ((('one', 0), ('subone', 0)), iTree('subone', value=1.1)), ((('one', 0), ('subtwo', 0)), iTree('subtwo', value=1.2)), ((('two', 0),), iTree('two', value=2)), ((('three', 0),), iTree('three', value=3))]
>>> [(k,i.value) for k,i in root.deep.tag_idx_paths()] # deep counterpart of level1 items(values_only=True) iterator
[((('one', 0),), 1), ((('one', 0), ('subone', 0)), 1.1), ((('one', 0), ('subtwo', 0)), 1.2), ((('two', 0),), 2), ((('three', 0),), 3)]
>>> [k for k,_ in root.deep.tag_idx_paths()] # deep counterpart level1 to keys() iterator
[(('one', 0),), (('one', 0), ('subone', 0)), (('one', 0), ('subtwo', 0)), (('two', 0),), (('three', 0),)]
>>> [k for k,_ in root.deep.idx_paths()] # no level 1 counterpart (lists are automatically indexed 0->n)
[(0,), (0, 0), (0, 1), (1,), (2,)]
iTree Filter Queries
A lot of the in-depth methods contain the parameter filter_method that can be used for hierarchical inside filtering of iTree-items. For non-hierarchical filtering the user can use the build-in filter()-method. In case an outside filtering is not possible (filter() cannot be used) the methods have an additional parameter hierarchical to switch in between the two ways of filtering.
As filter_method the user can give a callable object that analysis the given item and calculates if the item matches to the specific criteria and deliver a True/False (match/no match) for the item.
The iTree-class contains no more the old find()`and `find_all() methods because all searches can be realized easier and more clear via the filter_method-parameter.
Also we do not have any more a special ´iTFilter`-class, we decided that normal filtering via filtering methods is more practicable. As a help for the user we still provide some filter classes/methods under itertree.itree_filters that might help related to the filtering of iTree specifics.
>>> root = iTree('root', subtree=[iTree('one', 1, subtree=[iTree('subone', 1.1), iTree('subtwo', 1.2)]), iTree('two', 2), iTree('three', 3)])
>>> filter1 = lambda i: 'one' not in i.tag
>>> list(root.deep.tag_idx_paths(filter1))
[((('two', 0),), iTree('two', value=2)), ((('three', 0),), iTree('three', value=3))]
>>> # the hierarchical filter did not consider the item iTree('subtwo',1.2) because parent is filtered out
>>> list(filter(lambda i: 'one' not in i[1].tag, root.deep.tag_idx_paths())) # for non-hierachical filtering use build-in
[((('one', 0), ('subtwo', 0)), iTree('subtwo', value=1.2)), ((('two', 0),), iTree('two', value=2)), ((('three', 0),), iTree('three', value=3))]
>>> # now the sub-items are considered even that parent did not match
A very special filtering can be realized in the get()-method by putting filters in the related levels of a target_path (level filter).
E.g.:
root.get(Filters.is_item_tag('mytag'),Filters.is_item_tag('mytag2'))
Here we filter in first level for all items with the tag ‘mytag’ and in next level for all items with the tag ‘mytag2’.
The filter is used only at the specific level (in side one level we can just filter) but in the next level only the findings of first level will be considered. Therefore the level filtering is a hierarchical filtering which means only the matching items of the previous level are considered in the next level..
>>> # based on the root object we had in last example
>>> filter_a = lambda i: 'one' in i.tag # This will filter for the first two elements
>>> filter_b = lambda i: i.value == 1.2 # First element doesn't have this level (no match)
>>> root.get(*[filter_a, filter_b]) # level filtering level=0~filter_a; level=1~filter_b
[iTree('subtwo', value=1.2)]
The filtering in iTree is very effective and quick (if the filter function itself is quick). As an example one might execute the example script itree_usage_example1.py or calendar_example.py. It’s recommended that the user uses iterator related functions to reach the expected results (e.g. see itertools package).
iTree full overview over the in-depth functionalities
We already talked about some of the in-depth features in the in previous chapters (access and iterators) but now we like to complete the related functionalities.
All related methods are available in a specific iTree-object via the subclass itree.deep.
iTree formatted output and storage
The iTree-object can be printed out via classical repr() or str() method, the second method delivers a shorten representation of the subtree.
- itertree.iTree.__repr__()
Create representation string from which the object can be theoretically be reconstructed via eval() (might not work in case of value-objects that do not have a working __repr() method)
- Return type:
str
- Returns:
representation string
- itertree.iTree.__str__()
String repr of the item stripping the subtree to the first and last element only and giving “..” inbetween
For full representation-string use repr().
- Returns:
shorten representation string
A formatted multi-line tree output is available too. If the parameter enumerate is set the items in the printed tree are also enumerated by the absolute index.
- itertree.iTree.renders()
render the iTree into a string
- Parameters:
filter_method (Union[Callable,None]) –
filter method that checks for matching items and delivers True/False. The filter_method targets always the iTree-child-object and checks a characteristic of this object for matches (see filter_method)
If None is given filtering is inactive.
The method uses the given filter always as an hierachical filter.
enumerate (bool) –
True - Add an enumeration before the items
False (default) - Output without enumeration
renderer (class) – Give another renderer class for different formatting
- Return type:
str
- Returns:
Tree representation as string
- itertree.iTree.render()
Print the rendered string of the iTree-object to the console (stdout).
- Parameters:
filter_method (Union[Callable,None]) – filter method that checks for matching items and delivers True/False. The filter_method targets always the iTree-child-object and checks a characteristic of this object for matches. If None is given filtering is inactive.
enumerate – add an enumeration before the rendered items
renderer – Render to be used (The given render is stored and will be used until another renderer is given).
- Returns:
(The renderer in Version 1.0.0 was improved and uses now ascii-only characters and delivers a smaller footprint).
For full serialization of the iTree-objects it’s recommended to use the internal dumps() method. If the internal methods are used (file storage is possible too) the result is represented and stored as a JSON artifact.
- itertree.iTree.dumps()
serializes the iTree object to JSON (default serializer)
- Parameters:
calc_hash – Tell if the hash should be calculated and stored in the header of string
itree_serializer – optional user defined serializer for iTree objects
- Returns:
serialized string (JSON in case of default serializer)
- itertree.iTree.loads()
create an iTree object by loading from a string
If not overloaded or reinitialized the iTree Standard Serializer will be used. In this case we expect a matching JSON representation.
- Parameters:
data_str – source string that contains the iTree information
check_hash – True the hash of the file will be checked and the loading will be stopped if it doesn’t match False - do not check the iTree hash
load_links – True - linked iTree objects will be loaded
itree_serializer – optional user defined serializer for iTree objects
- Returns:
iTree object loaded from file
- itertree.iTree.dump()
serializes the iTree object to JSON (default serializer) and store it in a file
- Parameters:
target_path – target path of the file where the iTree should be stored in
pack – True - data will be packed via gzip before storage
calc_hash – True - create the hash information of iTree and store it in the header
overwrite – True - overwrite an existing file
itree_serializer – optional user defined serializer for iTree obbjects
- Returns:
True if file is stored successful
- itertree.iTree.load()
create an iTree object by loading from a file
If not overloaded or reinitialized the iTree Standard Serializer will be used. In this case we expect a matching JSON representation.
- Parameters:
file_path – file path to the file that contains the iTree information
check_hash – True the hash of the file will be checked and the loading will be stopped if it doesn’t match False - do not check the iTree hash
load_links – True - linked iTree objects will be loaded
itree_serializer – optional user defined serializer for iTree objects
- Returns:
iTree object loaded from file
In the methods the serializer can be set and might be replaced by the users own serializing format.
The serializer for Version 1.0.0 is modified and the output format is no more compatible with the old format. The conversion of old files can be made via the helper script:
>>> from itertree.itree_serializer.itree_json_converter import Converter_1_1_1_to_2_0_0
>>> new_itree=Converter_1_1_1_to_2_0_0(old_source_file_path)
The new storage format was required because in Version 1.0.0 we now have only one iTree class that uses the flags parameter to be switched to read-only where we used a special class in the old implementation.
But beside this we wanted to have a better performance related to the serializing of the objects. We think that the readability is improved too. Even that this was not the main target. The new format is also 100% JSON compatible and can be read in by any JSON parser.
[
{
"TYPE": "itertree.iTree",
"VERSION": "2.0.0"
"HASH": "e7891f95dd2f2c85d4383a8772a317e11363c495dc65a278c821836846d06471",
},
[
[0,0,["root",0],[0,8]],
[1,0,["0",0],[0,8]],
[2,0,["0_0",0],[0,8]],
[3,0,["0_1",0],[0,8]],
[4,0,["0_2",0],[0,8]],
[5,0,["0_3",0],[0,8]],
]]
After the well readable header the user can see that the tree is stored in a flat list structure (which avoids RecursionError exceptions in the JSON parsers).
The formatting of the output is created in a way that each iTree item has its own row and the indentation-level gives the hint about the level in the tree. Each item is coded in JSON in the following way:
[level,family-idx,[tag-value,type-code],[value-value,type-code]]
In case the item has additional parameters they are coded like the tag and the value too. The family-index is only given for better readability of the files, it’s not used during the reconstruction of the object.
If the user uses the iTree class as a super object for his own class the new serializer should work even (as long as the related module containing the new class is imported). But we cannot ensure that any extension is stored, it can be that a modified serializer is required in this case.
We have also a dot generator available which may help to create a graphical representation of the tree but this is not deeply tested there might be limits and we cannot ensure that the shown order is always correct.
Related to serialization we like to remark that iTree-objects can be pickled (pickle(my_tree)) too.
iTree linked sub-trees
The iTree objects can be merged to one main tree from different source files by using the link parameter. The result is a merged iTree that contains all the linked subtrees. Beside the linking from different files links inside a iTree structure (internal links) can be defined too.
The value of the link parameter of the iTree-class must be an iTLink`object which defines the `file_path and the target_path. The parameters are dependent. For links inside the same iTree the file_path must be set to None. For links targeting the root of a file the target_path parameter must be set to None. The target_path must target a unique item in the source-tree!
Figure showing how “sub3” links to “sub1” item and “inherits” it’s subitems beside the local ones
Additionally the user can manipulate the linked items by making them local (covering) or by appending local items. The functionalities given here are limited to operations that do not imply a reordering of the items in the tree. The reason for this is that the linked items cannot be reordered furthermore they gave the tree a fixed, static structure. E.g. mainly we have append() and make_local() functions and we cannot appendleft() or insert() because this would mean we have to reorder the other items. A change of a linked structure can only be made by manipulating the original source structure. We allow only the localization of items that are a child of the linked root item, in deeper levels this is not possible.
The local items in a linked iTree are integrated in the tree during the load process of the linked items. The identification is always made via the key (family-tag,family-index) of the item. The local storage of the tree contains iTree items that are merged as placeholders which will be replaced by the linked in items during the load process. Those placeholders are needed to create the matching key for the real items that should be kept after reload. In case the loaded structure is changed and and no matching item is found the placeHolder-items will remain in the iTree. All appended local items which are outside of the linked structure will be always positioned at the end of the tree.
Local items can be manipulated as normal iTree items with one exception. In case a local item is deleted and a matching linked item is available (was covered by the local item) the linked item will replace the local item after deletion. This means in this case a delete of an item will not reduce the numbers of the items. If the local item has no corresponding linked item the number of children will decrease as usual.
The linked items must be loaded and updated by an explicit operation. They are not loaded automatically. For this the method load_links() is used. The method can be executed at any level of the tree and it will start loading all links in the related subtree (use load_links()). By this mechanism incremental loads are possible. If the user wants to be sure that all linked items are loaded he must use the method in the root-object of the tree (load all links).
The behavior in case of load erros can be switched between Exceptions or deleting invalid items (via the delete_invalid_items parameter of the load_links()-method). In case of exceptions the iTree might be in an incomplete load state and if the exception is kept by the user this situation must be must be handled somehow (e.g. copy original tree before loading and replace back). The automated loading iTree links during instance of the object can be influenced via the flags=iTFLAG.LOAD_LINKS parameter that will activate the loading during instance.
Warning
The user must be aware that changing the source structure and local items in parallel might lead to unexpected results. The identification of local items is always done via the key (family-tag,family-index). If we miss items during load placeholders are used to keep the key of the “real” local items. Normally those artefacts will be replaced during the load with the “real” linked items (if found) but in case of mismatches they will stay in the tree. Using wild linking in between different iTree items can lead into very confusing situations especially if the user removes local items. We recommend to use the feature only in special cases where the source architecture is clearly defined and remains structural relative stable. For stability reasons we have also functional limitations in linked iTree objects (e.g. we do allow only linking on not already linked items (protection for circular definitions); local items can never be linked items.
- itertree.itree_main.iTree.load_links()
Runs ove all children and sub children in case a ITreeLink object is found the linked items are load in
In case ´iTree´ is link root: load all linked items
- Parameters:
force –
False (default) - load only if not already loaded
True - load even if already loaded (update)
delete_invalid_items –
False (default) - in case of invalid items we will raise an exception!
True - invalid items will be removed from parent no exception raised
_items – internal list parameter used for recursive calls of the function
_depth – Internal parameter related to current item depth
- Returns:
True - success
False - load failed
- property iTree.is_linked
In contrast to iTreeLinked class this is False
- Return type:
bool
- Returns:
True/False
- property iTree.is_link_root
property that marks the iTree item as an item that contains a link
- Returns:
True - is a link root item
False is no iTree link item
- property iTree.is_link_loaded
- property iTree.is_placeholder
Property shows that item is a placeholder class
Normally there should be no placeholder class in the iTree but in case a loaded link does no more contain the expected items it might happen that such a class artifact is still in the tree. In placeholders the value contains the family index in the linked class.
- Return type:
bool
- Returns:
True/False
Beside this the following specific functions are available on linked items:
- itertree.itree_main.iTree.make_local()
make the current linked object a local object This is only possible if the parent is a iTree object is the link root-> only the first level children in a linked iTree can be made local The operation raises an SyntaxError in case it is used on a deeper level of the linked tree
- Returns:
None
For a better understanding please have a look in the example file examples/itree_link_example1.py in the package. That contains the following examples too.
Special functionalities related to linking of iTrees:
To link a subtree in an iTree-object the link=iTLink(file_path,target_path) is defined when the object is instanced. A link cannot be added later on to the object.
>>> # We create a small iTree:
>>> root = iTree('root')
>>> root += iTree('A')
>>> root += iTree('B')
>>> B = iTree('B')
>>> B += iTree('Ba')
>>> # we create multiple 'Bb' elements to show how the placeholders are used during save and load
>>> B += iTree('Bb')
>>> B += iTree('Bb')
>>> B += iTree('Bc')
>>> root += B
>>> # !! Now we create a internal link (but we disable the loading (no flag set))):
>>> # (internal link -> iTLink(file_path==None,target_path= item identification) (target_path like in get_deep())
>>> linked_element = iTree('internal_link', link=iTLink(target_path=[('B', 1)]))
>>> root.append(linked_element)
iTree('internal_link', link=iTLink(None,[('B', 1)]), flags=0b100000)
>>> root.render()
iTree('root')
> iTree('A')
> iTree('B')
> iTree('B')
. > iTree('Ba')
. > iTree('Bb')
. > iTree('Bb')
. > iTree('Bc')
> iTree('internal_link', link=iTLink(None,[('B', 1)]), flags=0b100000)
>>> root.load_links() # now we load the linked items
True
>>> root.render() # The tree renderer marks linked items with ">>"
iTree('root')
> iTree('A')
> iTree('B')
> iTree('B')
. > iTree('Ba')
. > iTree('Bb')
. > iTree('Bb')
. > iTree('Bc')
> iTree('internal_link', link=iTLink(None,[('B', 1)]), flags=0b100100)
. >>iTree('Ba')
. >>iTree('Bb')
. >>iTree('Bb')
. >>iTree('Bc')
As shown in the example the internal linked item contains now the same subtree as the item (“B”,1). But they are integrated as linked iTree objects which protects the items from changes (readonly). If we change the items in the “B” item the changes are only considered if we reload the links in the tree!
>>> root['B', 1] += iTree('B_post_append')
>>> root.render()
iTree('root')
> iTree('A')
> iTree('B')
> iTree('B')
. > iTree('Ba')
. > iTree('Bb')
. > iTree('Bb')
. > iTree('Bc')
. > iTree('B_post_append')
> iTree('internal_link', link=iTLink(None,[('B', 1)]), flags=0b100100)
. >>iTree('Ba')
. >>iTree('Bb')
. >>iTree('Bb')
. >>iTree('Bc')
>>> root.load_links() # The returning True signalizes that the tree was reloaded
True
>>> root.render()
iTree('root')
> iTree('A')
> iTree('B')
> iTree('B')
. > iTree('Ba')
. > iTree('Bb')
. > iTree('Bb')
. > iTree('Bc')
. > iTree('B_post_append')
> iTree('internal_link', link=iTLink(None,[('B', 1)]), flags=0b100100)
. >>iTree('Ba')
. >>iTree('Bb')
. >>iTree('Bb')
. >>iTree('Bc')
. >>iTree('B_post_append')
>>> root.load_links() # If we repeat the action the command detects that the tree is unchanged and no update is needed
False
>>> root.load_links(force=True) # Anyway the update can be forced
True
The toplevel linked iTree-object allow some manipulations of the subtree. We can append items and we can convert the linked sub-items into local-items that covers the linked item and that can contain different values and a different subtree. But we cannot change the order of the linked items! Therefore the commands like insert() or append_left() are not allowed.
>>> intern_link_item = root['internal_link', 0] # get the linked item
>>> intern_link_item.append('new') # append a local item
iTree(value='new')
>>> local = intern_link_item[2].make_local() # make a linked item local (cover the item with a local one)
>>> local.append(iTree('sublocal')) # we change the subtree of the local item
iTree('sublocal')
>>> local.set_value('myvalue') # we change the value of the local item
<class 'itertree.itree_helpers.NoValue'>
>>> root.render() # see that in the linked tree we have local elements (linked items are marked with ">>")
iTree('root')
> iTree('A')
> iTree('B')
> iTree('B')
. > iTree('Ba')
. > iTree('Bb')
. > iTree('Bb')
. > iTree('Bc')
. > iTree('B_post_append')
> iTree('internal_link', link=iTLink(None,[('B', 1)]), flags=0b100100)
. >>iTree('Ba')
. >>iTree('Bb')
. > iTree('Bb', value='myvalue')
. . > iTree('sublocal')
. >>iTree('Bc')
. >>iTree('B_post_append')
. > iTree(value='new')
The item ‘Bb’ in the linked subtree is now no more an iTreeLink object, its a normal iTree object. The identification of the covering item is internally always done via the TagIdx of the item. We can do all iTree related operations on this object. But there is one exception: if we delete the object the linked object will come back into the tree!
>>> del intern_link_item[('Bb', 1)]
>>> print(root.render())
iTree('root')
> iTree('A')
> iTree('B')
> iTree('B')
. > iTree('Ba')
. > iTree('Bb')
. > iTree('Bb')
. > iTree('Bc')
. > iTree('B_post_append')
> iTree('internal_link', link=iTLink(None,[('B', 1)]), flags=0b100100)
. >>iTree('Ba')
. >>iTree('Bb')
. >>iTree('Bb')
. >>iTree('Bc')
. >>iTree('B_post_append')
. > iTree(value='new')
None

The link functionality in iTrees can be understood like the overloading mechanism of classes. By linking a subtree in the tree this is like defining a superclass for a specific tree section. By making a subitem local this part of the linked iTree is covered (overloaded). But we should not stress this analogy to much because the functionalities in this covered data structures are much less then we have it in the class concept.
There are some quite difficult to understand aspects related to the linking of items. The ordering of loading the linked items and the mixing with the local items might be confusing. Especially if the user stores such iTree-objects in files and when the source is manipulated. The main order is always given by the linked elements and there keys (tag-idx-pairs). A not loaded but linked tree contains all local elements and placeholder items that mark where in the linked tree the local elements should be placed in. From the concept the local items where no linked counterpart is found will be always placed before the next linked local item (if it’s a “real” one or a placeholder). All not filled local items will appended at the end during the load_links() process.
The most confusing things may happen if the user re orders the link source in a way that elements from the end are moved to the beginning. Original load scheme:
locals |
linked |
result |
iTree(‘link0’)
|
iTree(‘link0’)
|
|
iTree(‘tag1’)
|
iTree(‘tag1’)
|
|
iTree(‘tag2’,value=’new_value’)
|
iTree(‘tag2’,value=’link_value)
|
iTree(‘tag2’,value=’new_value’)
|
iTree(‘tag4’)
|
iTree(‘tag4’)
|
|
iTree(‘tag5’,value=’new_value’)
|
iTree(‘tag5’,value=’link_value)
|
iTree(‘tag5’,value=’new_value’)
|
iTree(‘tag6’)
|
iTree(‘tag6’)
|
Lets change the order of the source in the following way:
>>>root[('tag5',0)].move(('tag2',0))
After load_links() we will find the following situation
locals |
linked |
result |
iTree(‘link0’)
|
iTree(‘link0’)
|
|
iTree(‘tag4’)
|
iTree(‘tag4’)
|
|
iTree(‘tag5’,value=’new_value’)
|
iTree(‘tag5’,value=’link_value)
|
iTree(‘tag5’,value=’new_value’)
|
iTree(‘tag1’)
|
iTree(‘tag1’)
|
|
iTree(‘tag2’,value=’new_value’)
|
iTree(‘tag2’,value=’link_value)
|
iTree(‘tag2’,value=’new_value’)
|
iTree(‘tag6’)
|
iTree(‘tag6’)
|
In the linked source the cursive items have changed their position and the connected local items follow them.
The user might understand that the linked structure and order is somehow the main principle of ordering and the local items always follow this structure. So after the source is reordered the local items are reordered too. The local items that have no counterpart following always the anchor element afterwards (The item with ‘tag4’ is glued to ‘tag5 and the item with ‘tag1’ is glued with ‘tag2’).
iTree - extensions
The itertree-package contains some extensions especially related to the build of data models which can be optionally used to determine the data stored in the iTree-value attribute.
Predefined Filters
As a help for filtering on iTree-objects the user can find the following predefined filter classes/methods under itertree.itree_filters :
- itertree.itree_filters.has_item_flags()[source]
Check the iTree flags for match to the given flag mask
- Parameters:
item – iTree-item to be checked against the criteria of the method (for filtering out or not)
flag_mask – flag mask E.g. can be build like: iTFLAG.READ_ONLY_TREE|iTFLAG.READ_ONLY_VALUE
- Return type:
bool
- Returns:
True -> match
False -> no match
- itertree.itree_filters.is_item_tag()[source]
Check the iTree tag is equal to the given target_tag
- Parameters:
target_tag – tag string do not give Tag() objects here! Use Tag().tag if really required
invert –
False (default) -> unchanged result
True -> invert the result True->False; False->True
- itertree.itree_filters.has_item_tag_fnmatch()[source]
Check the iTree tag is matching to given fnmatch match_pattern
- Parameters:
match_pattern – str or bytes related to fnmatch pattern definitions
- itertree.itree_filters.has_item_value()[source]
Check the iTree value is equal to given value
- Parameters:
target_value – value object that should be equal with iTree.value
invert –
False (default) -> unchanged result
True -> invert the result True->False; False->True
- itertree.itree_filters.has_item_value_dict_value()[source]
Check if in case the iTree value is a dict a value in the dict is equal to given value
- Parameters:
target_value – value object that should be equal with iTree.value
invert –
False (default) -> unchanged result
True -> invert the result True->False; False->True
- itertree.itree_filters.has_item_value_list_value()[source]
Check if in case the iTree value is a list a value in the list is equal to given value
- Parameters:
target_value – value object that should be equal with iTree.value
invert –
False (default) -> unchanged result
True -> invert the result True->False; False->True
- itertree.itree_filters.has_item_value_fnmatch()[source]
Check if value matches to the given fnmatch pattern
- Parameters:
target_value_pattern – str or bytes related to fnmatch pattern definitions
invert –
False (default) -> unchanged result
True -> invert the result True->False; False->True
- itertree.itree_filters.has_item_value_dict_value_fnmatch()[source]
Check if in case the iTree value is a dict a value in the dict matches to the given pattern
- Parameters:
target_value_pattern – str or bytes related to fnmatch pattern definitions
invert –
False (default) -> unchanged result
True -> invert the result True->False; False->True
- itertree.itree_filters.has_item_value_list_item_fnmatch()[source]
Check if in case the iTree value is a list a value in the list matches to the given pattern
- Parameters:
target_value_pattern – str or bytes related to fnmatch pattern definitions
invert –
False (default) -> unchanged result
True -> invert the result True->False; False->True
- itertree.itree_filters.is_item_value_in()[source]
Check if iTree value is in the given iTInterval object, no numeric values will be ignored
- Parameters:
target_key_interval – msetInterval object defining the range (any object that supports “in” can be used)
invert –
False (default) -> unchanged result
True -> invert the result True->False; False->True
- itertree.itree_filters.has_item_value_dict_value()[source]
Check if in case the iTree value is a dict a value in the dict is equal to given value
- Parameters:
target_value – value object that should be equal with iTree.value
invert –
False (default) -> unchanged result
True -> invert the result True->False; False->True
- itertree.itree_filters.has_item_value_list_value()[source]
Check if in case the iTree value is a list a value in the list is equal to given value
- Parameters:
target_value – value object that should be equal with iTree.value
invert –
False (default) -> unchanged result
True -> invert the result True->False; False->True
- itertree.itree_filters.has_item_value_dict_key()[source]
Check if in case the iTree value is a dict a key in the dict is equal with the given target_key no numeric values will be ignored
- Parameters:
target_key – dict key
- itertree.itree_filters.has_item_value_list_idx()[source]
Check if in case the iTree value is a list the given target_key is lower than list length (inside) no numeric values will be ignored
- Parameters:
target_idx – target-index
invert –
False (default) -> unchanged result
True -> invert the result True->False; False->True
- itertree.itree_filters.has_item_value_dict_key_fnmatch()[source]
Check if in case the iTree value is a dict a key in the dict matches to the given key pattern (fnmatch) no numeric values will be ignored
- Parameters:
target_key_pattern – str or bytes related to fnmatch pattern definitions
invert –
False (default) -> unchanged result
True -> invert the result True->False; False->True
- itertree.itree_filters.has_item_value_dict_key_in()[source]
Check if in case the iTree value is a dict a key in the dict is in the given iTInterval object range no numeric values will be ignored
- Parameters:
target_key_interval – msetInterval object defining the range (any object that supports “in” can be used)
invert –
False (default) -> unchanged result
True -> invert the result True->False; False->True
Data Models
To control the data that can, be stored in an iTree-object value attribute (see :ref:`iTree value related methods`_) the itertree package contains some special classes related to the definition of data-models. Those models determine what kind of object can be stored inside the model. For this the user can define the target data-type, range-conditions, etc. Even the output formatting for string representations can be defined in those models.
The models might be useful and can be adapted by the user. But it’s just an optional feature this is not related to the core functionality of itertree. The iTree-class can be used independent from this.
The main class for model definition can be found via the “Data” extension of itertree.
- itertree.Data.iTValueModel()
This is the replacement for the old iTDataModel()-class.
This class can be used to define data models for the values that might be placed in the iTree.
The model should define min more detail which value objects are accepted or not and it defines also how not matching objects are handled:
Deny the value and raise a ValueError exception
Cast the value into a valid value object
But the definition of the data model allows limitations which goes far away from just data-type related topics. E.g. In the model the user can limit numerical values to a specific range (interval) or he might limit strings to specific characters.
All definitions related to checks and type casts must be defined by the user by overwriting the method check_and_cast_single_item(value_item) . The return of the method must e the checked and cast value. if the value does not match the method should raise a ValueError .
The method should always check and cast a single item, this is important. In case a list or an array like value should be stored in the model the base model will manage the required iteration over the sub-items and perform and utilize the single item check via the user defined method.
Note
In case a value like [1,2,3,45] is given each item in the list will be checked and/or casted.
This leads us to an important second definition functionality related to the model related to the size of dimensions (shape) of the value stored in the model. The definition of the shape is given as a parameter when the object is instanced. For the shape we expect a tuple with the dimension information. If a value object is given the maximum shape will be calculated and this will be compared with the expected one. The maximum is used because in nested lists the user can define sub-list with different length. Strings or bytes aare also seen as arrays in this case!
We have the following possibilities to define shapes:
shape=Any -> accept any shape of the given value (no check performed)
shape=tuple() -> empty tuple given no dimension expected model will accept single values only!
shape=(Any,) -> tuple containing one element which is the Any helper class; We will accept single values or any 1 dimensional object here (e.g. values like: 1; ‘abc’; [1,2,3,4] )
shape=(10,) -> tuple containing one element. We expect one dimensional values with a length lower or equal to the given integer number
shape=(INF,) -> tuple containing one element that is INF (infinite). We expect one dimensional values of any length
shape=(3,4) -> Two dimensions expected with fixed size (e.g. [[1],[2,3]] would match)
shape=(INF,4) -> Two dimensions expected with first length unlimited and second length limited to 3
shape=(4,ANY) -> Minimum one dimensions expected with first length limited to 4; here the user can also put infinite dimensions in (e.g [1]; [[1],[2]] ; [[[[888],[202,500]]]] would fit)
shape=(4,ANY,INF) -> 1 dimension or 3 dimensions accepted, 2 dimension will not be accepted
Note
The model base object iTValueModel() contains two checking levels. First the user defined check via method definition for checks and casts of single items given. In second step the model also checks the dimension (shape) of the given value.
In case a str or bytes objects are given the behavior related to the checks will be a bit different as for the other objects. The method check_and_cast_single_item(value_item) will target the whole string as a single item! But the shape check will be done also on the string as an object with a length.
This means a string is a 1 dimensional object and the user might limit the size of the string via a shape. (E.g.: The object “Hello” has the shape: (5,); the object [‘one’, ‘two’,’three’] has the shape: (3,5) ) The user might use the method ‘get_max_shape()’ to measure the shape of objects that is considered in the model base class.
During the instance of the object a formatter can be defined too. This might help the user e.g. do define if an integer value should be converted to a hex or binary representation during string conversion. The build-in command str() of this model class will deliver the formatted value only. The repr() will deliver the class definition.
To use the model the user should put the instanced model object as value in the iTree. The real value objects can be placed during object instance via the parameter value or later on via the set() method of the model (value exchange too). In case the value is not matching to the model definition an ValueError exception will be raised. If the user like to test first if the value is matching he can use the in keyword to check this. In case of no match the exception content might be picked via the last_exception property of the model in this case (might give a hint why the value is not accepted).
Standard Parameters:
- Parameters:
value – value object to be stored in the model (must match to the model). In case no value is stored in the model (empty model) the value will be NoValue.
description – Description string
shape –
Define the dimensions the object should have:
None - shape is ignored object might have dimensions or not
tuple() - empty tuple or iterable - value object will have no size/dimension
(InfShape) - one dimensional value object with infinite size
one dimensional value object with max size of 100 items
(100,100) - two dimensional object with max size of 100 in each dimension
(InfShape,InfShape,InfShape) - three-dimensional object with infinite size in each dimension
…
Note
For multi-dimensional objects it’s recommended to use numpy arrays or objects which have the attribute shape representing the size for each dimension available instead of tuples or lists. If not the object performance might be worse (internal iterations required to measure the shape).
formatter – Formatter for the single item of the value object (see string formatting in python) In case no formatter is given str() will be used for creation of the item string representation.
To give the user an idea how this class might be used and for practical proposes we already defined a set of value models for typical data types:
- itertree.Data.iTAnyValueModel()
Model that will take any python object without any restrictions
- itertree.Data.iTRoundIntModel(value=<class 'itertree.itree_helpers.NoValue'>, description=None, shape=<class 'itertree.itree_helpers.Any'>, contains=None, formatter=<class 'str'>)
Model that would store integer values The model accepts any object that can be casted into a float and rounded to an integer to be stored as a int in the model
- itertree.Data.iTIntModel()
This integer model allows only integers or strings containing a decimal integer to be stored in the model as int value
- itertree.Data.iTInt8Model()
Integer model that limits the given values to int8 values
- itertree.Data.iTUInt8Model()
Integer model that limits the given values to uint8 values
- itertree.Data.iTInt16Model()
Integer model that limits the given values to int16 values
- itertree.Data.iTUInt16Model()
Integer model that limits the given values to uint16 values
- itertree.Data.iTInt32Model()
Integer model that limits the given values to int32 values
- itertree.Data.iTUInt32Model()
Integer model that limits the given values to uint32 values
- itertree.Data.iTInt64Model()
Integer model that limits the given values to int64 values
- itertree.Data.iTUInt64Model()
Integer model that limits the given values to uint64 values
- itertree.Data.iTFloatModel()
Float model that allows any float or string that can be casted to float to be stored in the model as float value
- itertree.Data.iTStrFnPatternModel()
A model to store a string that matches to the fnmatch pattern
- itertree.Data.iTStrRegexPatternModel()
A string model that matches to the regex pattern
- itertree.Data.iTASCIIStrModel()
A string model that accepts only ASCII characters
- itertree.Data.iTUTF8StrModel()
A string model that accepts only UTF-8 characters
- itertree.Data.iTUTF16StrModel()
A string model that accepts only UTF16 characters
Mathsets extension
The itree package contains a extension we named mathsets which are a special kind of sets that can be used for range definitions in data-models but also for filtering a specific content.
The main check method for those kind of objects is the __contains__-method which is target via the build-in in statement.
The mathsets are a fragment of a new package that might be published in the future. The idea is mainly to extend the Python set() in a more mathematical way by adding for example interval sets and by allowing the user to define those sets by giving a mathematical definition string.
Therefore those classes might be interesting for the user independent from the usage related to iTree-objects. Especially the class mSetInterval is a full representation of a mathematical interval which allows also mathematical based object definitions like: “{x| x e Z, -128<=x<128}”
In itertree we have two main classes of mSets available:
- itertree.itree_mathsets.mSetInterval()[source]
Mathematical interval set object. Here the user can define a mathematical interval with closed or open boarders.
For more details related to mathematical intervals you may have a look here: https://en.wikipedia.org/wiki/Interval_(mathematics)
- itertree.itree_mathsets.mSetRoster()[source]
super class for all mSet objects
handles two parameters :param vars: variable names set :param complement: complement flag
Additional we have a helper classes that allows to combine those mathsets with each other or other objects (like normal Python sets).
- itertree.itree_mathsets.mSetCombine()[source]
class where the user can combine different sets to unions
In this class the user can combine different types of sets (all objects with __contains__() and a length are allowed to be added.
If the object is used to check if a value is in it is sufficient if the value is in one of the subsets to create a positive response for a match
These for classes are targeting numerical set definitions (Intervals, RosterSets, numerical domains). see https://en.wikipedia.org/wiki/Set_(mathematics) and https://en.wikipedia.org/wiki/Interval_(mathematics).
After we have presented the available classes we should give an idea of the usage. What might be the use case for this? In an application we might have the following needs:
We must create for the usage of the application a complex configuration
The configuration should be structure in a tree
The user should be capable to edit the value content of the attributes stored in the tree
The app should check if the given values are valid for the targeted attribute
The configuration should be shown in a GUI with a string representation
Some attributes contains range definition for tolerances
The user should be capable to define those tolerances with the help of mathematical descriptions
The most challenging attribute is in this case a tolerance definition that can be given by the user. Exactly for this case the mathset functionalities are very helpful.
iData
The “old” iData-class which was used as standard data-structure in iTree-objects in older versions is still available but must be added manually to the iTree as value object.
The object is in practice a dict-like structure which helps to manage the stored data values. But we would recommend to use normal dictionaries with data models in the items as a replacement.
Comparison of the iTree object with lists and dicts
In first case the iTree behaves like a list. Therefore all list related operations are supported in iTree-objects. Additionally in iTree we have the dict specific key related operations available too.
The following table compares the behaviors (x is always the related object)
Operation |
iTree |
list |
dict |
append |
x.append(item)
|
x.append(item)
|
x[new_key]=item
|
appendleft |
x.appendleft(item)
|
x.insert(0,item)
|
n.a.
|
append by +=
|
x+=item
|
x+=item
|
n.a.
|
extend
|
x.extend(items)
|
x.extend(items)
|
n.a. - x.update(items)
goes in same direction
-> (overwrites existing keys)
|
extendleft
|
x.extendleft(items)
|
n.a. - you migth change
the target/source you are extending
and use normal extend
|
n.a. - x.update(items)
goes in same direction
-> (overwrites existing keys)
|
insert
|
x.insert(target,item)
|
x.insert(index,item)
|
n.a.
|
delete
|
del x[target]
|
del x[index]
|
del x[key]
|
pop specific
|
x.pop(target)
|
x.pop(index)
|
x.pop(key)
|
pop last
|
x.pop() or x.pop(-1)
|
x.pop(-1)
|
x.popitem()
|
pop first
|
x.popleft() or x.pop(0)
|
x.pop(0)
|
n.a
|
remove
|
x.remove(value)
|
x.remove(value)
|
n.a.
|
move **
|
x[target1].move(,target2)
|
n.a.
|
n.a.
|
reorder
|
x[target1],x[target2],x[target3]= \
x[target2],x[target3],x[target1]
|
x[index1],x[index2],x[index3]= \
x[index2],x[index3],x[index1]
|
x[key1],x[key2],x[key3]= \
x[key2],x[key3],x[key1]
|
reorder by slices
|
x[target1:target3]= \
x[target2],x[target3],x[target1]
|
x[index1:index3]= \
x[index2],x[index3],x[index1]
|
n.a.
|
rename
|
rename(target1,target2)
|
n.a. -> x[index1]=x.pop(index2)
|
n.a. -> x[key1]=x.pop(key2)
|
__getitem__
|
x[target]
|
x[index]
|
x[key]
|
get(key,default)
|
x.get(target,default=None)
|
n.a.
|
x.get(key,default)
|
in depth get(target_path,default)
|
get(*target_path)
|
n.a. -> x[index1][index2]
|
n.a. -> x[key1][key2]
|
standard iterator,
|
iter(x) or x.iter(filter_method)
|
iter(x)
|
x.items()
|
keys iterator,
|
x.keys(filter_method)
|
range(len(x))
|
x.keys()
|
values iterator,
|
x.values(filter_method)
|
iter(x)
|
x.values()
|
items iterator,
|
x.items(filter_method)
|
enumerate(x)
|
x.items()
|
iter deep
|
iter(x.deep)
|
n.a.
|
n.a.
|
The target arguments used by iTree can be of different type and the result of the operations can be a single item or multiple items (iterator). Some operations which require unique targets will raise an exception if the target is not unique.
The following types/classes might be used as target parameter for the iTree related commands:
Tag(tag) - this key targeting a whole family of items (can be any hashable object)
(tag,index) - TagIdx object pointing to a specific item in a family
index - index integer number
[index1,index2] - A list of indexes targeting different items (works with iterators too)
iter([index1,index2]) - An iterator of indexes targeting different items (works with iterators too)
(tag,[index1,index2]) - A list of indexes targeting different items in a family
(tag,iter([index1,index2])) - An iterator of indexes targeting different items in a family
slice - slicing over items via index
(tag,slice) - Slicing over the indexes of a specific family
method - a method that is used for filtering of children (must deliver True/False)
** The difference in between move and reorder is that the move operation ensures that the original objects are kept. The reordering works only in case some of the objects are copied internally.
Special Typecasts
The iTree can be casted in lists and dicts in two ways:
Keep the ‘iTree’-child-objects:
>>> root = iTree('root',subtree=[iTree('one', 1, subtree=[iTree('subone', 1.1), iTree('subtwo', 1.2)]), iTree('two', 2), iTree('three', 3)])
>>> list(root)
[iTree('one', value=1, subtree=[iTree('subone', value=1.1), iTree('subtwo', value=1.2)]), iTree('two', value=2), iTree('three', value=3)]
>>> list(root.deep) # flatten deep item list
[iTree('one', value=1, subtree=[iTree('subone', value=1.1), iTree('subtwo', value=1.2)]), iTree('subone', value=1.1), iTree('subtwo', value=1.2), iTree('two', value=2), iTree('three', value=3)]
>>> dict(root.items())
{('one', 0): iTree('one', value=1, subtree=[iTree('subone', value=1.1), iTree('subtwo', value=1.2)]), ('two', 0): iTree('two', value=2), ('three', 0): iTree('three', value=3)}
>>> {k:i for k,i in root.deep.tag_idx_paths()} # flatten deep items dict
{(('one', 0),): iTree('one', value=1, subtree=[iTree('subone', value=1.1), iTree('subtwo', value=1.2)]), (('one', 0), ('subone', 0)): iTree('subone', value=1.1), (('one', 0), ('subtwo', 0)): iTree('subtwo', value=1.2), (('two', 0),): iTree('two', value=2), (('three', 0),): iTree('three', value=3)}
Consider just the stored values instead of the iTree-child-objects itself:
>>> root = iTree('root', subtree=[iTree('one', 1, subtree=[iTree('subone', 1.1), iTree('subtwo', 1.2)]), iTree('two', 2), iTree('three', 3)])
>>> list(root.values()) # targets only first level children deeper hierarchy is lost
[1, 2, 3]
>>> [i.value for i in root.deep] # flatten iterator delivering in-depth values of items
[1, 1.1, 1.2, 2, 3]
>>> dict(root.items(values_only=True)) # targets only first level children deeper hierarchy is lost
{('one', 0): 1, ('two', 0): 2, ('three', 0): 3}
>>> {k:i.value for k,i in root.deep.tag_idx_paths()} # in-depth levels are flatten in the iterator
{(('one', 0),): 1, (('one', 0), ('subone', 0)): 1.1, (('one', 0), ('subtwo', 0)): 1.2, (('two', 0),): 2, (('three', 0),): 3}
In this casts to dicts the unique tag-idx-key (or relative tag_idx_path for deep operations) is used as the key in dicts (we cannot use the tags itself because they might not be unique).
Use iTree with unique tagged items
As explained collects the iTree-class multiple items with the same tag in a tag-family. But if the user likes to use the iTree-class with unique tags only (comparable to dictionaries where keys are unique) the iTree-class supports some specific functionalities for unique tagged trees. This should help the user in such a situation.
As user may have already read in this tutorial, we have an access function in the get subclass for single items:
- itertree.itree_getitem._iTreeGetitem.single()
Call via iTree().get.single()
In general the methods does same like the “normal” get() but the method delivers only single (unique) results. In case get() delivers multiple items this method will raise an Exception or delivers the default value (if defined).
Note
In case the match contains a list with only one element the result is unique too. The method will unpack the unique item from the iterable and return it in this case.
- Except:
If default parameter is not set an KeyError or IndexError will be raised. If result is not unique a ValueError will be raised
- Parameters:
target (Union[int,tuple,list,slice]) –
level 0 target object targeting a child or multiple children in the ´iTree´. Possible types are:
index - absolute target index integer (fastest operation)
key - key tuple (family_tag, family_index)
index-slice - slice of absolute indexes
key-index-slice - tuple of (family_tag, family_index_slice)
target-list - absolute indexes or keys to be replaced (indexes and keys can be mixed)
key-index-list - tuple of (family_tag, family_index_list)
tag - family_tag object targeting a whole family
tag-set - a set of family-tags targeting the items of multiple families
itree_filter - method (callable) for filtering the children of the object
all-children - if build-in iter() or … (Ellipsis) is given a list of all children will be given (same result as list(itree.__iter__()) )
*target_path –
in-depth targets iterable of targets for the different levels 1-n The supported targets in each level are (same like __getitem__():
index - absolute target index integer (fastest operation)
key - key tuple (family_tag, family_index)
index-slice - slice of absolute indexes
key-index-slice - tuple of (family_tag, family_index_slice)
target-list - absolute indexes or keys to be replaced (indexes and keys can be mixed)
key-index-list - tuple of (family_tag, family_index_list)
tag - family_tag object targeting a whole family
tag-set - a set of family-tags targeting the items of multiple families
itree_filter - method (callable) for filtering the children of the object
all-children - if build-in iter() or … (Ellipsis) is given a list of all children will be given (same result as list(itree.__iter__()) )
default (object) – If parameter is set in case of no match the default object will be delivered. If parameter is not set an Exception will be raised
- Return type:
Union[iTree,object]
- Returns:
found single item or default (in case default is set)
If the user gives here just the family tag as parameter and the family really contains just one item (unique tag) the method will deliver the unique item back. It’s the “speciality” of the method to unpack items out of the list of family-items (normally delivered by iTree.get()) and in case of unique items it delivers the item directly.
But the method will raise an exception if the item is not found or what is more important if more than one item was found. (If the named parameter default is defined the default will be deliver instead of the exception raised.)
>>> root = iTree('root', subtree=[iTree('one', 1, subtree=[iTree('subone', 1.1), iTree('subtwo', 1.2)]), iTree('two', 2), iTree('two', 2.2),iTree('three', 3)])
>>> root['one'] # targets the family and will deliver a list which contains in this case only one item
[iTree('one', value=1, subtree=[iTree('subone', value=1.1), iTree('subtwo', value=1.2)])]
>>> root.get.single('one') # targets the same family but because we have just one value the item inside the list is delivered directly
iTree('one', value=1, subtree=[iTree('subone', value=1.1),iTree('subtwo', value=1.2)])
>>> root.get.single('two') # will raise an exception because we do not have a unique result
Traceback (most recent call last):
...
ValueError: No single item found
>>> root.get('one', 'subone') # targets in-depth and delivers the resulting list
[iTree('subone', value=1.1)]
>>> root.get.single('one', 'subone') # Same method exists in get sub-class too
iTree('subone', value=1.1)
So we see that unique items can be indeed targeted only via tag if the itree.get.single()-method is used but how can we set single items comfortable? For the setting (and replacement) of unique items the __setitem__()-method with two special targets can be used. For both targets the family of the given item will be deleted before the new item is integrated.
target: Ellipsis […] - given iTree-object will be appended to the tree
target: same family-tag as given item - given item will be inserted in the position of the first item of the deleted family.
Because the two targets ensure that the family is deleted before the item is integrated. The user can use them to integrate only unique tagged items in the tree. Different compared to the normal __setitem__() behavior the method will not raise an exception if the family-tag is not found in the tree. Furthermore the given new item will just be appended at the end of the already existing children.
Warning
IMPORTANT: The method will raise an exception if linked items found in the family! The reason is that we cannot reduce the number of items in the family if they are linked (original source must be modified for this). The single operation must be denied in this case.
>>> root['two'] # family 'two' contains two items:
[iTree('two', value=2), iTree('two', value=2.2)]
>>> root['two', 0].idx # index of first item in 'two' family
1
>>> root['two']=(iTree('two', 'new')) # replace the two items in the family 'two'
>>> root.get.single('two') # Now we get the unique item in this family
iTree('two', value='new')
>>> root.get.single('two').idx # Index is same as before!
1
>>> root['two']=iTree('two', 'new2') # replace again
>>> root.get.single('two')
iTree('two', value='new2')
>>> root.get.single('two').idx # Index is same as before!
1
>>> root[...]=iTree('two', 'new3') # replace and add at the end
>>> root.get.single('two')
iTree('two', value='new3')
>>> root.get.single('two').idx # Index is now last index
2
As we have seen the iTree-class supports the handling of unique tags by some special commands. But the iTree-object is no not at all blocked for taking multiple tags in this case If the user utilizes other methods (e.g. standard append()) the object will still take multiple items with same tag! And the functions using tag_idx will still expect/deliver the tuple: (tag,family-index) (but family-index is always 0 for unique tags).
Related to performance we must remark that the tag_idx access (via ìtree[(tag,idx)] or itree.get.tag_idx((tag,idx)) is quicker as the tag only access via itree.get.single(tag). This should be considered in costly operations (e.g. loops).
If the user likes to “clean” an iTree-object from multiple children with same tag and only the first items in the families should resist he may run the code:
for tag_idx_path,item in list(itree.deep.tag_idx_paths()):
if tag_idx_path[-1][-1]==0 and item.parent: # an already deleted items might not have a parent
item.parent[item.tag]=item